【原创】 十六、价值投资基础知识
价投基础知识与认知
一、估值计算
同比: 指当年的某个月与去年相同的月份进行对比
环比:指本次统计段与相连的上次统计段之间的比较
1、什么是PE ?
PE:市盈率,股票估值指标,股价与每股收益的比率; PE=股价/每股收益。
高PE:可能意味着市场对该公司未来的增长预期很高,也可能意味着股票当前被高估。
低PE:可能意味着市场对该公司前景不看好,也可能意味着股票当前被低估,是买入的好机会。
2、什么是静态市盈率?
静态市盈率的本质是 “股价与过去一个完整会计年度净利润的比值”。
计算公式:静态市盈率 = 当前股价 / 上一年度每股收益(EPS) 或者 静态市盈率 = 当前总市值 / 上一年度净利润
TTM 是 “Trailing Twelve Months” 的缩写,意思是“过去十二个月”。所以,P/E TTM 就是用公司过去已经公布的、“最近12个月”的净利润来计算出的市盈率。
3、什么是动态市盈率?
动态市盈率(Dynamic P/E 或 Forward P/E,简称 PE(动))是股票估值中一个非常重要的指标。它和静态市盈率的主要区别在于所使用的“净利润”数据不同。
计算公式:动态市盈率 = 当前总市值 / 未来预测的总净利润 或者 动态市盈率 = 当前股价 / 未来预测的每股收益(EPS)

4、预测和分析(新易盛案例)


5、什么是PEG指标?
一、核心定义
PEG指标(市盈率相对盈利增长比率)是在市盈率(PE)的基础上发展而来的一个进阶估值指标。它的核心目的是解决一个关键问题:
“一家公司的市盈率这么高,到底合不合理?它的高增长能 justify 它的高估值吗?”
PEG的计算公式为:
PEG = 市盈率(PE) / 净利润增长率(Growth Rate)
市盈率(PE):通常使用动态市盈率(PE动),即基于未来12个月的预测盈利来计算。
净利润增长率(Growth Rate):通常指公司未来几年预期的年均净利润增长率(以百分比表示,但计算时不带百分号)。
二、为什么需要PEG?—— 从PE的缺陷说起
单纯使用市盈率(PE)估值有一个巨大的缺陷:
公司A:PE为30倍,但明年利润预计能增长50%。
公司B:PE为15倍,但明年利润预计零增长。
如果只看PE,公司B更“便宜”。但显然,公司A的高增长使其可能更具投资价值。PE指标无法将“增长”这个关键因素量化进估值里。
PEG的诞生,正是为了将公司的市盈率与其盈利增长速度直接联系起来,从而更公允地评估不同成长性公司的估值水平。
三、如何解读PEG值?
PEG指标的理论由投资大师彼得·林奇(Peter Lynch) 发扬光大,他对其解读提供了一个经典的基准:
PEG = 1:
意味着公司的市盈率与其盈利增长率相匹配,估值处于“合理”或“公允”的水平。理论上,这是一家成长性与估值非常匹配的公司。
PEG < 1:
意味着公司的市盈率低于其盈利增长率。通常这表明公司可能被低估了(即股价“便宜”),因为投资者可以用较低的价格买到较高增长的公司。PEG越小,理论上低估的可能性越大。
PEG > 1:
意味着公司的市盈率高于其盈利增长率。通常这表明公司可能被高估了(即股价“偏贵”),市场为其增长支付了过高的溢价。PEG越大,高估的可能性越大。
简单来说,PEG的核心思想是:追求用尽可能低的市盈率,购买尽可能高的盈利增长。
四、如何计算PEG?—— 一个详细的例子
假设我们分析一家公司:
当前股价:100元
今年预测每股收益(EPS):5元(因此其动态PE = 100 / 5 = 20倍)
未来三年预测的年均净利润增长率:25%(分析师综合预测)
那么,它的PEG计算如下:
PEG = 动态PE (20) / 增长率 (25) = 0.8
由于PEG=0.8 < 1,根据理论,这家公司可能处于被低估的状态,考虑其较高的增长率,20倍的PE显得并不贵。
五、使用PEG指标的注意事项(非常重要!)
PEG是一个非常强大的工具,但它严重依赖于输入数据的质量,使用时必须谨慎:
增长率预测的准确性是关键:
PEG中的“G”是对未来的预测,而不是历史数据。这个预测来自券商分析师、公司指引或投资者自己的判断。预测永远是错的,只能尽可能接近现实。对于周期性行业或业务不稳定的公司,预测误差会很大,PEG的参考价值会降低。
选择正确的PE:
一定要使用动态市盈率(Forward PE),即基于未来盈利的PE。使用静态市盈率(Past PE)计算PEG会得出非常误导性的结论。
统一计算口径:
确保PE和G的时间周期匹配。如果PE是基于未来一年的盈利(2025年),那么G就应该是未来一年的增长率(2025年 vs 2024年)。更常见的做法是,PE用未来一年的,G用未来3-5年的年均复合增长率。
PEG更适用于成长股:
该指标对于盈利稳定增长的公司最有效。对于周期性公司、陷入困境的反转型公司或利润波动极大的初创公司,PEG可能不太适用。
不能孤立使用:
PEG只是一个估值工具,不能作为投资的唯一依据。必须结合公司的基本面分析、行业前景、竞争优势、管理层质量等因素综合判断。
总结
PEG指标是市盈率(PE)的优化版本,它通过引入盈利增长率(G),将估值与成长性捆绑评估,解决了“高PE是否合理”的问题。
PEG ≈ 1:估值合理
PEG < 1:可能低估(值得关注)
PEG > 1:可能高估(需要警惕)
二、段永平对企业未来现金流折现和估值具体思路
核心观点: 段永平并不是在真正地、精确地积算仪各公司的DCF(现金流折现),他多次强调,DCF不是一个计算公式而是一种思维方式!!!
核心思路:
1. 定性分析优先: 在思考任何数字之前,首先要判断这家公司是不是一家“好公司”。好公司的标准是:
· 强大的护城河: 拥有强大的品牌(如茅台)、技术领先(如苹果),使得竞争对手难以超越。
· 优秀的商业模式: 能持续产生充沛的自由现金流,并且不需要持续的大额资本支出来维持竞争力。
· 可信赖的管理层: 管理层以股东利益为导向,诚实、能干。
2. 思考未来现金流的确定性: 对于筛选出的好公司,重点思考其未来(比如5年、10年甚至更久)赚取自由现金流的能力是否足够稳定和可预测。如果一家公司的未来现金流非常模糊、波动巨大,那么它就不适合用DCF(现金流折现)思维来估值。
3. “毛估估”代替精确计算: 基于对公司的深刻理解,对一个“大概”的未来现金流和其增长率进行估算。关键在于 “宁要模糊的正确,不要精确的错误” 。他追求的是一个价值区间,而不是一个精确的数字。
具体步骤(“毛估估”版DCF)
虽然不进行精确计算,但其思考过程暗含了DCF的逻辑。我们可以将其分解为以下步骤:
步骤一:找到“正确的石头”——选择标的
这是所有步骤的前提。只选择那些你真正理解、商业模式简单、现金流稳定的好公司。段永平的投资组合(苹果、茅台、腾讯等)都符合这个特征。
步骤二:估算未来一段时间的自由现金流
1. 确定当前的自由现金流: 找到公司目前能产生的“所有者盈余”(经营活动产生的现金流量净额)。一个简化的算法是:自由现金流(更纯的所有者盈余) = 经营活动现金流净额 - 资本性支出。
因为企业为了维持现有的生产经营能力,必须进行必要的资本再投资(如更换老旧设备、升级厂房)。扣除这部分维持性支出后剩余的现金流,才是企业可以自由支配且不会损害其未来竞争力的“盈余”,这部分才能真正安全地分配给所有者或用于新的发展机会。
资本性支出:
① 购置新的固定资产:如土地、厂房、机器、设备、车辆。
② 购置新的无形资产:如软件、专利、许可证。
③ 对现有资产进行重大升级、改造和扩建。
④ 为战略性扩张而进行长期的资产投资。
注意:财报中的“投资活动产生的现金流量”部分,一个关键的行项目:“购建固定资产、无形资产和其他长期资产支付的现金”,这是一个非常直接地反映企业当期资本性支出现金总额的指标。
2. 估算一个保守的增长率: 根据对行业前景、公司竞争力的理解,给未来5-10年一个保守的、可持续的增长率。例如,对于茅台,他可能会认为其销量和价格在未来10年有一个稳定的低速增长。
3. 估算第一阶段的价值: 将未来几年(比如10年)的现金流,以一个保守的增长率进行估算,并加总。这是一个简化的“高速增长期”模型。
步骤三:确定折现率
段永平对折现率的看法非常经典。他认为折现率就是无风险收益率,通常用长期国债的利率(2.3% -- 2.5%)作为参考。
· 逻辑是: 投资一家公司的最低要求回报,至少要高于无风险收益。如果一家公司的预期回报率还比不上国债,那为什么不直接买国债呢?
· 实际操作: 他会用一个相对固定的比率,比如5%或10%,来简化思考。这个比率反映了他的机会成本和对风险的最低要求回报。
步骤四:估算永续价值
这是DCF模型中最关键也是最难的部分。段永平的简化方法是:
1. 假设永续增长率为0: 为了保守起见,他通常假设公司在高速增长期结束后,进入零增长阶段,其价值就等于一个永续年金。
2. 计算公式(简化版):
· 永续价值 = 第N年的自由现金流 / 折现率
· 例如,如果估算10年后公司的年自由现金流是200亿,折现率是5%,那么永续价值 = 200 / 5% = 4000亿。
3. 将这个永续价值折现到现在,加上第一阶段现金流的现值(将未来几年的现金流,以一个保守的增长率进行估算,并加总),就得到了企业的大概内在价值。
总内在价值 = 永续价值折现 + 第一阶段现金流的现值
一个简化的实例(以茅台为例)
假设我们正在“毛估估”茅台的价值:
1. 定性判断: 茅台品牌无敌,护城河极深,商业模式好(先款后货,现金流极好)。这是一块“正确的石头”。
2. 估算当前现金流: 假设茅台目前年自由现金流约为800亿元。
3. 估算未来增长: 保守估计,未来10年其自由现金流能以每年6%的速度增长。
· 第1年后的现金流 ≈ 800 * (1.06)^1 ≈ 848亿元。
......
......
· 10年后的现金流 ≈ 800 * (1.06)^10 ≈ 1432亿元。
4. 确定折现率: 采用5%作为折现率(高于长期国债利率,考虑了机会成本)。
5. 计算永续价值:
· 10年后的永续价值(假设零增长)= 1432 / 5% = 28,640亿元。
· 将永续价值折现到今天 = 28,640 / (1.05)^10 ≈ 17,582亿元。
总内在价值 = 17582+第一年 + 第二年 +...... + 1432 = 大约30000亿(未详细计算)
6. 得出结论: 茅台的内在价值大概在3万亿左右。然后与当前市值比较,如果当前市值远低于这个“毛估估”的价值,就可能是一个好的投资机会。
总结与精髓
段永平的DCF方法,精髓在于:
1. 思维模型而非计算工具: 它强迫你从企业所有者的角度去思考生意本身,关注其长期现金创造能力。
2. 追求模糊的正确: 承认未来的不可预测性,通过保守的假设(低增长率、高折现率/零永续增长)来寻求安全边际。
3. 能力圈原则: 只对少数你能理解的、商业模式简单的公司使用这种方法。
4. 简单化: 避开了复杂的财务模型和变量预测,直指核心——这家公司在它的生命周期里,能为股东带回的现金,比我现在付出的价格多吗?
最终,段永平通过这种思维方式,将投资的复杂问题简化为一个本质问题:用4毛钱的价格,去购买价值1块钱的资产。 DCF思维就是帮助他判断那个资产“到底值1块钱还是8毛钱”的思考框架。
三、市场中轻资产行业分类
“轻资产行业”通常指那些资本投入较少、固定资产占比较低、更多依赖无形资产(如智力资本、品牌、技术、网络和人力资本)来运营和创造价值的行业。其核心特点是:固定成本低,可变成本高,扩张的边际成本低,因此通常具有较高的毛利率和较强的 scalability(可扩展性)。
1. 互联网
① 软件开发
例子:微软(Office 365)、Adobe(Creative Cloud)、Salesforce、用友网络、金山办公。它们主要投入在研发上,产品通过云端交付,几乎没有实物库存。
② 互联网与社交平台
例子:腾讯(微信、QQ)、字节跳动(抖音、TikTok)、微博、Meta(Facebook, Instagram)。它们构建平台,连接用户和内容创作者/商家,通过广告、增值服务等盈利。
③ 电子商务平台
例子:阿里巴巴(淘宝、天猫)、京东(平台业务)、拼多多、亚马逊(第三方 marketplace 业务)。它们自身不持有大量库存,而是为买家和卖家提供交易场所,赚取佣金和广告费。
④ 云计算与IT服务
一、一梯队
这些公司提供基础的计算、存储、网络资源,并在此基础上构建了庞大的云生态。
阿里巴巴-阿里云 腾讯-腾讯云 百度-百度云
二、二梯队,传统IT服务商转型
这些公司由传统的系统集成、软件服务商转型而来,在特定行业有深厚的客户积累。
金山软件、用友网络、东软集团、中国电信-天翼云 、中国移动-移动云
三、三梯队,垂直领域/专业云服务商
广联达:建筑信息化领域的龙头,其核心产品“数字造价”业务已全面转型为SaaS模式,是垂直SaaS云服务的典范。
恒生电子:金融科技领域的绝对龙头,为证券、基金、银行、期货等金融机构提供软件和云服务,其“云赢”、“云毅”等产品是金融云的代表。
深信服:最初以网络安全闻名,现在其云计算业务(超融合、桌面云)增长迅速,为企业提供“软件定义”的IT基础设施。
四、四梯队, IDC(互联网数据中心)服务商
万国数据:中国领先的高性能数据中心开发商和运营商,主要服务大型云厂商和互联网公司。
数据港:国内领先的数据中心服务提供商,与阿里云等有深度合作。
宝信软件:背靠宝钢集团,依托资源优势发展IDC业务,同时自身也是工业软件和IT服务解决方案提供商。
2. 科技研发类
① 人工智能行业
核心资产是算法团队和数据资产,依赖云算力开展业务,无需大量固定资产。比如智齿科技的 AI 客服、推想科技的智能医疗诊断系统,通过 API 调用、定制化模型开发盈利,毛利率常达 70%-90%。
② 半导体设计行业
采用 Fabless 模式,仅专注芯片设计,制造环节外包给台积电等代工厂,无需自建百亿级晶圆厂。像芯动联科的 MEMS 陀螺仪芯片、汇川技术的工业控制芯片,靠电路架构设计和 IP 授权实现 50%-70% 的高毛利。
② 精准医疗与生物技术行业
核心资产为研发团队和生物数据,实验室设备可租赁或外包。例如燃石医学的肿瘤 NGS 检测服务、英矽智能的 AI 药物研发平台,诊断服务和创新药相关业务毛利率普遍超 80%。
3. 专业服务类
① 咨询行业
管理咨询(麦肯锡、波士顿)、战略咨询、人力资源咨询、财务咨询。
② 法律服务
律师事务所、知识产权代理。
③ 会计与审计服务
会计师事务所、税务筹划公司。
④ 广告与营销策划
广告创意公司、数字营销机构、品牌策划公司。
⑤ 设计服务
UI/UX设计、平面设计、工业设计、建筑设计(部分为轻资产模式)。
4. 文化创意类
① 影视与娱乐制作
独立制片公司、短视频工作室、MCN机构。
② 游戏开发
尤其是独立游戏团队、手游开发商(依赖代码和创意而非硬件)。
③ 出版与内容发行
数字出版、电子书平台、自媒体出书。
④ 艺术与版权运营
IP授权、动漫形象运营、文创产品设计(外包生产)。
5. 金融与投资类
① 投资银行与券商
例子: 高盛、摩根士丹利、中信证券。主要业务如承销、并购顾问等,依赖人力资本和金融牌照。
② 资产管理
例子: 贝莱德、富达基金、华夏基金。通过管理客户的资产收取管理费,核心是投资研究能力。
③ 支付与金融科技
例子: 支付宝、PayPal、Visa、Mastercard。构建支付网络,处理交易流,赚取手续费。
6. 共享经济与平台型服务类
① 共享出行平台
如:滴滴、Uber(不拥有车辆,只提供平台)。
② 共享住宿平台
如:Airbnb、途家(不持有房产)。
③ 众包服务平台
如:猪八戒网(连接服务提供者与客户)。
7. 电商与新零售类
① 品牌电商运营(无自有工厂)
如:许多DTC品牌(Direct-to-Consumer),通过代工生产+线上销售。
② 跨境电商(轻模式)
如:Shopify独立站卖家、亚马逊FBA卖家(仓储由平台负责)。
③ 社区团购平台
仅做信息撮合与供应链管理,不自建物流。
8. 健康与个人服务类
① 在线医疗咨询
医生在线咨询平台,不设实体医院。
② 健康管理与健身指导
如:线上私教、健康APP、营养咨询服务。
③ 心理咨询与辅导
在线心理咨询服务,依赖专业人才而非场地。
例子: 专科诊所(如牙科、眼科连锁)、互联网医疗平台(如平安好医生)。更依赖医生技术和品牌,而非大型医疗设备。
总结:轻资产行业的共同特点!!!
核心价值在于无形资产:品牌、专利、版权、技术、数据、人力资本、商业模式。
固定资产占比低:不需要大量投资在厂房、机器设备上。
运营杠杆高:一旦核心系统/平台建成,服务额外客户的边际成本很低。
现金流通常较好:由于前期资本开支小,现金回收快。
易于快速扩张和复制:例如,一个成功的软件或商业模式可以迅速推广到全球。
四、商业模式优秀、盈利能力强、负债率低的行业
在国内,能够被称为商业模式顶尖、利润丰厚、负债率低的行业,通常具备以下几个核心特征:
高毛利率 & 高净利率
轻资产运营(低资本开支)
强定价权或垄断/寡头格局
现金流充沛、分红稳定
护城河深(品牌、牌照、网络效应等)
1、白酒(高端白酒)
特点:
毛利率 >80%,净利率 >40%(如茅台净利率超50%)
几乎零应收款、预收款模式(先款后货)
库存不贬值反而升值(老酒越存越值钱)
品牌护城河极深,难以被替代
资产负债率普遍低于30%
2、互联网平台/数字经济(头部企业)
特点:
轻资产、高毛利(软件/服务为主)
用户规模带来数据和流量壁垒
现金流好,资本开支相对可控
头部企业净利率可达20%-40%+

3、免税零售(政策垄断)
国家特许经营、牌照稀缺、利润率惊人
特点:

4、医疗服务/创新药(细分龙头)

5、软件与信息技术服务(Saas、金融科技)

6、公用事业中的优质行业(水电、核电)

7、消费类垄断品牌

【原创】 七、有关经济的一些基础知识

基础知识与认知
一、CPI指标
同比: 指当年的某个月与去年相同的月份进行对比
环比:指本次统计段与相连的上次统计段之间的比较
1、什么是CPI ?
消费者物价指数,又称居民消费价格指数
2、CPI上涨与下跌的影响?


二、PPI指标
1、什么是PPI ?
PPI指的是生产价格指数,反应的是工业品出厂价格的变化,PPI下降表名原材料价格跌幅比较大,PPI下降是不好的,但也不是越高越好,它的波动反应了实体经济的景气程度。
2、PPI指标调查的商品?
燃料、化工原料、钢材、木材、水泥、农副产品、工控产品等,主要用来预测未来物价变化的宏观经济数据指标。
三、经济放水
1、经济放水的代表“安bei经济学”
大概意思理解为,经济不好的时候ZF把钱花出去,带动经济发展。
弊端:往一个池子注水注多了以后,水会涨起来。同样的道理,经济放水以后股市会涨、债券会涨、商品价格会涨,物价会上升。
加息:最近几年疫情影响,包括美国在内的一些国家为了保住经济,进行大放水,放水以后物价上涨,石油、粮食、猪肉、能源等等都在涨,物价上涨,钱就不值钱了。 为了控制气球吹大以后不会自己爆,就要放点气,怎么放呢,通过加息。因为钱是临时应对不景气的经济,从ZF那里印出去的,当然要收回来。当美国进行加息以后,那些在美国贷款的人就要回去还本金+高额利息,在世界范围内的投资者自然要抛掉手中股票、房产、债券等回去还钱。
CPI:2022/8/10 美国公布CPI比上一期降低,比预期还低0.2个点,这样美国ZF就会放缓加息的预期,美股大涨,A50也大涨,2022/8/11世界范围内的资金也放心的开始流动,内资外资都在爆买。美国ZF放缓加息的预期,同时美元指数在下跌,人民币以及非美货币就会有一定的升值, 如果人民币下跌,就会导致一些外资的出逃(美元必须兑换成人民币才能买进A股,如果人民币下跌,兑换成人民币以后哪怕不买股票只是逛一圈,资产就缩水了),2022/8/11美元指数下跌,人民币汇率反弹,外资回流,几十亿上百亿的外资回流,肯定是不会去小盘子股的,要去也是去蓝筹股、金融股等,所以2022/8/11当天动的是券商(金融)、茅台、五粮液、歌尔股份、中国船舶、比亚迪等蓝筹股
四、世界经济与美国经济
1、美元成为国际货币的历史因素
在二战以后,美国逐渐确立了其在世界经济和军事领域的领先地位,欧洲大陆国家与美国达成协议同意使用美元进行国际支付,此后美元作为储备货币在美国以外的国家广泛使用并最终成为国际货币。
要想成为国际货币,除了汇率稳定以外,还有其他系列因素,更多的政治因素。至于美元还能在世界上使用多少年,还取决于世界其他国家的发展和美国自身的发展。
五、股市级别
1、点
买卖点、K线、MACD、等等xx指标
2、线
热点板块、市场人气/市场情绪、图形(头肩顶、M顶、W底、多头排列等等)
3、面
资金流向、经济指标、国家CPI数据、美国CPI数据、美国加息、世界经济形势、世界大宗商品价格、地缘政治等等
六、解禁
1、解禁
股票解禁是指公司股票持有人在规定时间内可以自由出售其持有的股票。在企业股票上市时,可能会存在股票锁定期,期间股东不得出售其持有的股票。一旦锁定期结束,股票就会解禁,股东可以自由出售其持有的股票。
通常情况下,当一个公司的股票解禁之后,其股票供应量会增加,这可能会影响股票价格。如果解禁的股票数量很大,市场供应将会更加充裕,可能导致股票价格下跌。
七、一级市场和二级市场
股市的一级市场和二级市场存在几个主要的区别:
1、交易性质:
一级市场:一级市场是公司通过发行股票或其他金融工具来筹集资金的场所。在这个市场中,投资者直接购买公司发行的新股,这些股票通常来自公司的首次公开募股(IPO)。一级市场的交易对公司来说是首次发行股票的过程。
二级市场:二级市场是指公司股票在一级市场发行并上市后,投资者之间互相买卖股票的地方。在这个市场中,股票价格的变动不受公司股本变动的影响,而是取决于市场供需关系和其他多方面的因素。
2、交易主体:
一级市场:交易主体包括上市公司、投资者、股票承销商等。一级市场的参与者通常是直接与公司接触的个人或机构投资者,他们可能会参与公开发行或定向发行过程。
二级市场:二级市场的交易主体主要是个人投资者和机构投资者。他们在二级市场上进行的交易是不受公司股本变动影响的,因此不需要考虑公司内部的变化,更多的是关注市场行情和技术分析等因素。
3、交易方式和规则:
一级市场:一级市场的交易方式包括公开发行和定向发行两种。公开发行的股票会在证券监管部门注册登记,而定向发行则是向特定对象发行股票。
二级市场:二级市场的交易方式包括集中竞价和协议转让两种。集中竞价是通过证券交易所的电子系统进行撮合的交易方式,而协议转让则是在证券交易所之外通过双方协商确定的交易方式。
4、流动性:
一级市场:一级市场上的股票可能存在限售期,在这段时间内股票不能上市交易流通。因此,一级市场的流动性相对较低。
二级市场:二级市场的股票没有限售期,交易比较自由,流动性相对较高,通常在交易时间内可以随时交易。
5、信息透明度:
一级市场:一级市场是非公开的,信息的透明度相对较低,投资者在投资时需要更多的信息和判断力。
二级市场:二级市场是公开的,投资者可以通过各种渠道获取相关信息,这使得市场情绪可以被利用。
八、什么是重资产企业
1、释义
高额固定资产投入:公司的资产负债表上,“固定资产”科目金额非常庞大,占总资产的比重很高。启动和运营需要巨大的前期投资。
高折旧成本:厂房、机器设备等会随着时间推移而损耗贬值,这部分价值会以“折旧”的形式计入当期成本,侵蚀企业利润。
高财务杠杆:由于初始投资巨大,企业往往需要通过银行借款或发行债券来融资,导致资产负债率较高,财务风险也随之增加。
规模经济效应明显:一旦固定资产投入完成,产量越大,单位产品所分摊的固定成本(如折旧)就越低,企业就越能盈利。因此,它们非常追求产能利用率和市场规模。
进入和退出壁垒高:
进入难:新竞争者很难筹集到足够的资金来复制同样的生产设施。
退出难:那些昂贵的专用设备很难转卖或转作他用,沉没成本极高。
2、行业举例
汽车制造、钢铁厂、半导体芯片制造(台积电)、能源资源行业、交通运输(航空公司购买飞机、铁路公司铺设铁轨)、大型连锁超市(购买租赁土地房产) 、顺丰(自购飞机、建设机场、中转中心)
九、什么是轻资产企业
1、释义
与重资产企业相对的是轻资产企业。这类企业主要依靠自身的知识产权、品牌、人力资本、管理流程、客户关系等无形资产来创造价值,而不依赖于拥有大量的有形固定资产。
2、行业举例
互联网公司:阿里巴巴、腾讯、
软件公司:微软、Adobe
品牌管理公司:如耐克(主要专注于设计和营销,生产大多外包)。
咨询公司:如麦肯锡(核心资产是人才和知识)。
十、资产负债率
1、释义
资产负债率是衡量企业财务结构和风险水平的核心指标,计算公式为:
资产负债率 = 总负债 ÷ 总资产 × 100%。该指标越高,通常代表企业的 “负债依赖度” 越强,但具体含义需结合行业特性、企业阶段和财务策略综合判断,不能简单等同于 “风险高” 或 “经营差”。
资产负债率的本质是 “企业资产中有多少是靠借钱形成的”。例如,资产负债率 60% 意味着:企业每 100 元资产中,有 60 元来自负债(如银行贷款、应付账款),仅 40 元来自股东投入(净资产)。
指标越高,说明企业对外部资金(负债)的依赖程度越高,自身权益资金的 “撬动作用” 越强 —— 这种 “以债扩资” 的模式,既是一把 “双刃剑”,也反映了企业不同的经营逻辑。
十一、同比环比
1、同比
定义:同比是指与上年度的同一时期进行比较。
计算公式:同比增长率 = (本期数值 - 上年同期数值) / 上年同期数值 × 100%
2、环比
定义:环比是指与紧相邻的上一个统计周期进行比较。
计算公式:环比增长率 = (本期数值 - 上期数值) / 上期数值 × 100%
十二、定增
1、定义:“企业搞定增” 指的是上市公司通过定向增发(简称“定增”)的方式再融资。
定向:意思是“面向特定对象”,不是所有股民都能买。
增发:意思是“增发新股”,公司新发行一部分股票。
合起来就是:上市公司选择一些特定的、符合条件的投资者(通常数量不多),以一定的价格向他们新发行一批股票,从而从这些投资者手里融到一笔资金。
2、定增的关键特点
① 打折买股票:为了吸引这些大佬来投资,定增的价格通常会有折扣,比市价要低一些(一般是不低于市价的80%)。这是定增对投资者最大的吸引力之一。
② 锁定期:这些“大佬”买了定增股票后,不能马上卖掉套现。按照规定,他们有至少6个月的锁定期(如果认购后成为公司控股股东或实际控制人,则锁定期为18个月)。这保证了公司资金的稳定,也防止他们短期套利走人。
③ 特定投资者:这些“大佬”不是普通人,通常是:
实力雄厚的机构投资者(如公募基金、私募基金、证券公司、信托公司等)
有资源的战略投资者(比如公司的上下游合作伙伴,能带来业务协同效应)
少量的超级富豪(个人资产门槛很高)
十三、投资的本质
1、定义:忘掉是在买股票,想象自己是在做一门生意。
2、生意的本质
① 它如何赚钱?(盈利模式)
靠卖产品?(茅台卖酒)、提供服务?(腾讯云提供云服务)、收取佣金?(券商)
② 它赚钱容易吗?
品牌护城河:(如茅台) 用户愿意为品牌支付溢价。
网络效应护城河:(如微信、抖音) 用户越多、价值越大,新来者难以超越。
技术护城河:(如台积电、苹果) 拥有别人难以轻易复制的专利或者技术。
特许经营护城河:需要政府拍照,准入门槛极高。
......
3、现金流本质
投资的回报,最终必须真实的体现为现金流的回报。
① 未来自由现金流折现 (公司可以自由支配,不影响经营的钱)
4、市场预期的本质
市场价格(股价)并不总是等于内在价值,价格围绕价值波动,而驱动波动的,是市场预期。
价格 VS 价值
① 价格是你付出的,价值是你得到的。
② 投资的奥秘在于:在市场预期低迷,价格远低于内在价值时买入;在市场预期狂热,价格远高于内在价值时卖出。
5、人性的本质
这是最难的一关,因为你要对抗的是自己的“人性”。
① 贪婪与恐惧
② 从众,没有自我主见,别人说什么就跟随什么,而自我主见需要具有深刻的了解与认知。
③ 过度自信与厌恶损失 赚钱了,自己能力,亏损了,归咎于市场
总的来说,投资的本质就像“剥洋葱”
① 最外层(现象):价格波动、新闻消息、K线图。
② 中间层(分析):市场预期、情绪博弈。
③ 最内层(核心):生意的本质+现金流价值+对人性的克服。
真正的投资,永远穿透表层的喧嚣,直达最内层的核心,用合理的价格,买入一门能持续产生丰厚现金流的好生意,并有足够的耐心与定力陪伴其成长。
十四、战争和海峡关闭对我国经济的影响
1、战争对经济的影响
① 外部
大宗商品:
战争威胁主要产油区(如中东)或运输要道(霍尔木兹海峡),直接引发能源(油气煤化工)、金属等战略物资的供给担忧和运输成本飙升。输入性通胀压力:油价上涨会直接推高国内生产和物流成本,挤压中下游企业利润。同时,黄金等贵金属和战略资源因避险需求进入价格上升周期。例如,近期美伊冲突就曾导致中国"三桶油"历史上首次集体涨停。
金融市场:
全球避险情绪升温,资金会从风险资产(股票)流出,转向美元、黄金等传统避险资产
宏观政策:
战争引发的全球通胀(尤其是油汽价上涨)可能打乱主要经济体的货币政策节奏,如推迟降息甚至重启加息
短期:短期内的剧烈波动往往是情绪和预期的集中释放,短期波动影响比较大。
中长期:而中长期的经济走向则更多取决于战争持续时间、受损程度以及本国经济的基本面与政策应对
② XX冲突
毫无疑问,不要带丝毫犹豫和幻想,直接跑就对了,不是简单的区域性冲突,是从“估值逻辑”到“生存逻辑”的急转直下。
2、海峡关闭对我国经济的影响
① 霍尔木兹海峡(伊朗与阿曼之间海峡)
油气开采与油服:利润大幅上涨
油运与航运:运价大幅上涨
贵金属:资金涌入黄金、白银等贵金属避险
军工:军工表现活跃,和军事装备有关的稀有金属企业股价也得到资金关注
② 苏伊士运河(埃及控制,连接地中海与红海)
集装箱航运:绕行非洲南部好望角,相关航运公司盈利能力增强
物流:物流成本上升,利润压缩
出口欧洲企业:运价飙升和运输时间延长,对中国出口至欧洲的家具、家电、机械等商品的成本造成压力,可能影响相关企业的短期出口竞争力和订单。
③ 马六甲海峡
位于马来半岛(马来西亚和泰国南部)与印度尼西亚的苏门答腊岛之间的漫长海峡,由新加坡、马来西亚和印度尼西亚三国共同管辖,治理权在沿岸三个国家中。
进口依赖型企业:推高中游企业原材料采购价格,利于上游资源、矿产开采企业。
港口与航运:贸易量预期下滑,航运板块承压。
④ 巴拿马运河(巴拿马境内)
巴拿马运河主要连接太平洋和大西洋,对美国东海岸、南美西海岸与亚洲之间的贸易至关重要。其关闭主要影响特定航线。
美东航线航运:从亚洲到美国东海岸的船只若无法使用运河,将被迫绕行南美洲合恩角,航程和成本急剧增加。这将直接利空主营美东航线的航运公司。
农产品贸易:美国出口至亚洲的粮食(大豆、玉米等)以及南美出口至亚洲的矿产(铜矿石等)严重依赖该航线。关闭将导致农产品和矿产供应链受阻,可能推高国内豆粕、铜等期货价格,利好国内农业和矿业板块。
十五、外部因素导致霍尔木兹海峡关闭的持续影响 (输入性通胀)
1、短暂几天--几周
① 数据:全球约 20%--30% 海运原油、20% LNG 经此运输,中国约 50% 原油进口依赖该通道。
② 冲击:油价跳涨、油轮运价飙升(短期一两天炒作)、避险情绪升温、通胀预期抬头。
③ 传导:风险资金偏好下降 → 资金从成长/科技 / 消费流出 → 涌入确定性强、抗通胀、地缘受益板块。
④ 受益板块
油气开采/油服股涨逻辑 :油价暴涨→上游开采利润增厚;油服订单随勘探开发加速而爆发。 (注意:第一)
中国石油、中国石化、中国海油、中海油服、杰瑞股份、石化机械、贝肯能源、山东墨龙等。
煤炭股涨逻辑:原油涨价→煤炭、天然气替代需求提升→价格跟涨;高股息 + 业绩双驱动。 (注意:第二)
中国神华、陕西煤业、广汇能源、水发燃气、宝丰能源。
化工股涨逻辑:伊朗是甲醇、乙二醇、尿素、钾肥主产国→出口受阻→国内产品涨价;自给率高的企业受益。(注意:第三)
宝丰能源(甲醇)、云天化(化肥)、华鲁恒升、卫星化学。
油运: (注意:第四)
中远海能、招商轮船、招商南油、中远海控。
养殖股涨逻辑:供应链脆弱性暴露的背景下,"粮食安全"和"农业安全"的战略地位被提升到前所未有的高度,化肥涨价+粮价涨价+饲料成本涨价+避险资金抱团。
温氏股份、大北农、巨星农牧、隆平高科、农发种业等。
黄金股涨逻辑:地缘冲突 + 通胀预期→资金涌入黄金避险 (避险+抗通胀)
山东黄金、中金黄金、赤峰黄金、紫金矿业。
军工股涨逻辑:情绪 + 地区紧张→军备采购预期 + 军贸订单提升;安全主题强化。(注意:本条支线逻辑较弱)
总结:石油/天然气 > 煤炭 > 化肥 > 黄金 > 种植业/养殖 >军工
【原创】 Linux 用户管理和服务管理

五、Linux用户管理和服务管理
一、用户管理命令
摘要:
用户信息文件: /etc/passwd
user1:x:500:500::/home/user1:/bin/bash

第一列:用户名
第二例:密码位(x代表设置了密码)
第三列:UID 用户ID
0: 超级用户
1-499: 系统用户(伪用户,不允许登录linux,绝对不允许删除,是用来启动linux服务或者命令或者程序的)
>500: 普通用户 (默认500-60000)
第四列:GID 初始组ID
第五列:用户说明
第六列:家目录
第七列:用户登录之后的权限
/bin/bash
影子文件: /etc/shadow (用户密码保存文件,权限000,root也要wq!才能保存)
组信息文件: /etc/group
sc : x : 500 :
组名:组密码位:组ID:组中附加用户

windows创建的用户都在user组


1、添加用户
useradd 用户名 添加用户
useradd 选项 用户名
选项:
-g 组名 指定初始组 不要手工指定
-G 组名 指定附加组,把用户加入组,使用附加组
-c 说明 添加说明
-d 目录 手工指定家目录,目录不需要事先建立
-s /bin/bash 手工指定用户登录之后的权限
-u uid: 指定UID

useradd -g aa bb 添加bb用户,同时指定初始组为aa
useradd -G user1 aa 添加用户aa,指定附加组为user1
gpasswd -a 用户名 组名
useradd -g 组名 用户名
user1:
初始组:每个用户初始组只能有一个,一般都是和用户名相同的组作为初始组
附加组:每个用户可以属于多个附加组,要把用户加入组都是加入附加组
2、设定密码
passwd 用户名
passwd 改变当前用户密码
passwd user1 改变user1用户密码
3、删除用户
userdel -r 用户名 -r连带家目录一起删除
4、添加组
groupadd 组名
5、删除组
groupdel 组名 注意:组中没有初始用户
6、把已经存在的用户加入组
gpasswd -a 用户名 组名 把用户加入组

gpasswd -d 用户名 组名 把用户从组中删除
二、用户相关命令
1、id 用户名 显示用户的UID,初始组合附加组

2、su - 用户名 切换用户身份 - 连带环境变量一起切换
env 查看Linux操作环境
三、ACL权限 用来解决用户对文件身份不足的问题
举例:/work 项目提交目录
所有者、所属组有提交更改创建权限,其他人无任何权限
leigong --> 所有者
lggroup --> 所属组
/work/ 权限 770
操作:
mkdir /work
chmod 770 /work/
useradd leigong
groupadd lggroup
gpasswd -a leigong lggroup (所有者加入组)
将所有者leigong加入到lggroup组中
gpasswd -a user1 lggroup (用户user1加入组)
将用户user1加入到lggroup组中
chown leigong:lggroup /work
ll -d /work/

1、getfacl 文件名 查询文件的acl权限
2、setfacl 选项 文件名 设定acl权限
-m 设定权限
-b 删除权限

班主任以5权限进到了work目录

删除facl权限

setfacl -m u:用户名:权限 文件名
setfacl -m g:组名:权限 文件名
setfacl -m u:aa:rwx /test 给test目录赋予aa是读写执行的facl权限
setfacl -m u:cc:rx -R soft/ 递归赋予acl权限,只能赋予目录
-R 递归
setfacl -b /test 删除acl权限
setfacl -x u:用户名 文件名 删除指定用户的ACL权限
3、setfacl -m d:u:bzr:5 -R /work/ acl设置默认权限 d(default)


注意:默认权限只能设置目录
注意:如果给目录赋予acl权限,两条命令都要输入
setfacl -m u:用户名:rx -R 文件名 只对已经存在的文件生效
setfacl -m d:u:bzr:rx -R 文件名 只对未来要新建的文件有效
四、输出重定向和多命令顺序执行
1、输出重定向 (把应该输出到屏幕的输出,重定向到文件)
> 覆盖的方式写进文件
>> 追加的方式写进文件
ls > aa 覆盖到aa
ls >> aa 追加到aa
ls fdhfjsolk 2>>aa 错误信息记录到aa文件 2 错误信息 注意:错误输出,不能有空格

掌握:
ls >> aa 2>&1 错误和正确都可以输入到aa,可以追加, 2&1把标准错误重定向到标准正确输出
ls >> aa 2>>/tmp/bb 正确信息输入aa,错误信息输入bb
五、服务和进程管理
进程管理三个主要任务:
判断服务器健康状态 正常、非法 top
查看所有正在运行的进程 ps pstree
强制终止进程 kill pkill
服务器合理资源范围 70/90:内存占用不超过70%,CPU占用不超过90%
一、进程查看
1、ps aux 查看当前系统所有运行的进程
-a 显示前台所有进程
-u 显示用户名
-x 显示后台进程
服务器遵循70/90原则,即内存占用率不超过70%,CPU占有率不超过90% !!!

user: 用户名
PID: 进程ID PID=1的进程永远是/sbin/init 系统启动的第一个进程
%CPU: CPU占用百分比
%MEM: 内存占用百分比
VSZ: 虚拟内存占用量 KB
RSS: 固定内存占用量
TTY: 登录终端 tty1-7本地终端 1-6字符,7图形;pts/0 - 255 远程终端
STAT: 进程状态 S:睡眠 D:不可唤醒 R:运行 T:停止 Z:僵死 W:进入内存交换 X:死掉的进程 <:高优先级 N:低优先级 L:被锁进内存 s:含子进程 +:位于后台 l:多线程
START: 进程触发时间
TIME: 占用CPU时间
COMMAND: 进程本身
2、pstree 查看进程树
pstree -p 查看进程树(包括inode号)

3、top

第一行:系统当前时间 系统持续时间 登录用户数量 1,5,15分钟之前的平均负载
第二行:进程总数 进程总数125个,1个运行,124个休眠
第三行:CPU占用率 %id空闲辈分比
第四行:内存使用 总共 使用 空闲 缓存
第五行:swap使用
可通过1,5,15分钟之前的平均负载、CPU空闲率、内存空闲率判断服务器的基本压力
操作命令:
M:内存排序
P: CPU排序
q: 退出
4、进程管理 终止进程 (没事别老杀进程,apache、mysql等进程都有启动终止命令)
kill 信号 PID 结束单个进程
-9 强制
killall -9 进程名 结束一类进程
pkill -9 进程名 结束一类进程
w 判断登录用户

pkill -9 -t 终端号 把某个终端登录的用户踢出去(只有超级用户才能提其他用户)
pkill -9 -t pts/0 把user1用户踢下去,踢完之后user1用户连接状态变成了红色

六、Linux服务管理
默认情况下,所有的服务管理命令(如:service、ntsysv、chkconfig)都不能识别源码包安装的服务
一、分类
RPM包安装的服务
1、独立的服务 (独立服务放在内存,直接响应速度快;缺点占内存)
启动:
A:service 服务名 start|stop|restart
B:/etc/rc.d/init.d/服务名 start 标准启动
自启动:
A:chkconfig --level 2345(开机级别) httpd on|off
B:vi /etc/rc.local
/etc/rc.d/init.d/httpd start (建议用第二个)
2、基于xinnetd的服务 (xinetd服务自己占内存,它管理的服务部占内存,缺点慢;;用得越来越少)

ntsysv
源码包安装的的服务
启动
/usr/local/apache2/bin/apachectl start
自启动
vi /etc/rc.local
/usr/local/apache2/bin/apachectl start
二、系统默认安装的服务
1、确定服务分类
chkconfig --list 查看RPM包安装的服务的自启动状态
运行级别:0-6
0 关机
1 单用户模式
2 不完全多用户,不包含NFS服务
3 完全多用户,字符界面
4 未分配
5 图形界面
6 重启
init 0 关机
init 6 重启
【原创】 Linux IP配置

三、Linux IP地址配置
一、IP地址配置
1、配置IP
执行 setup
选择网络配置

选择设备配置

选择eth0 --> 回车

配置IP

Ok-->Save-->Save&Quit-->Quit
重启网络配置 service network restart
2、启用网卡
vi /etc/sysconfig/network-scripts/ifcfg-eth0
ONBOOT=no 修改为 ONBOOT=yes

重启网络配置 service network restart
3、修改虚拟机网络连接方式(只针对虚拟机生效)
把虚拟机网络连接方式选择桥接

4、选择桥接到哪一块网卡
编辑---虚拟网络编辑器---桥接到有线网卡

5、UUID(唯一识别符)(只针对刻录镜像)
如果执行以上重启网络,最后一行失败,执行以下
vi /etc/sysconfig/network-scripts/ifcfg-eth0
5.1、删除mac地址行重启一下就会换算UUID ,不要删除UUID 会导致无法连接

5.2、删除UUID绑定文件
rm -rf /etc/udev/rules.d/70-persistent-net.rules
5.3、重启 reboot
【原创】 Linux 软件安装

四、Linux 软件安装
一、软件包安装
服务器安装原则:最小化安装、使用什么软件安装什么、尽量不卸载
软件包选择原则:
如果软件安装之后,是给大量客户端提供访问的,建议源码包安装
如果软件安装之后,是给本机或者少量用户访问,建议二进制包
1、软件包分类
1.1 源码包:
优点:开源、自由定制、本机编译,所以效率高
缺点:编译时间长,一旦报错,很难解决
1.2 二进制包:(也叫rpm包)
优点:安装速度快,简易
缺点:不再开源、自定义性差、软件效率低、依赖性...
a包--->b包--->c包 树形依赖
a包--->b包--->c包--->a包 环形依赖
库文件依赖 去 http://www.rpmfind.net 找
2、rpm安装,两种安装方式(手工RPM命令安装和yum在线安装,yum是二进制的在线安装方式)
2.1 手工RPM命令安装
2.1.1 包命名
包名-版本号-发布次数-适合linux系统.适合的硬件平台.rpm
E16 ---> RHEL6
包全名:操作没有安装的软件包,软件包使用包全名 gvfs-fuse-1.4.3-12.el6.i686.rpm(完整名字是包全名)
包名:操作的是已经安装的软件包使用包名 gvfs-fuse(英文是包名)
2.1.2 依赖性
2.1.3 安装
rpm -ivh 包全名(绝对路径)
-i 安装 -v 显示详细信息 -h 显示进度
安装位置:默认位置 rpm安装最好不要指定安装位置(有卸载命令),源码包一定要指定安装位置(源码包没有卸载命令,直接删除安装目录)
rpm -Uvh 包全名
-U 升级
启动程序:
/etc/rc.d/init.d/httpd restart 其他linux启动命令
service httpd restart redhat linux转悠命令,其他Linux没有
2.1.4 卸载
rpm -e 包名
在生产服务器不管是安装还是卸载都不允许强制,必须正确解决依赖性
2.1.5 查询
a:查询软件包是否安装
rpm -q 包名 查询包是否安装
rpm -qa | grep httpd 显示所有安装包
b:查询包信息
rpm -qi 包名 查询包的信息 -p 未安装的包

rpm -qip 包全名 查询没有安装包的信息 -i information

c:查询软件安装位置
rpm -ql 包名 查询包中文件的安装位置 l -->list 列表的意思
rpm -qlp 包全名 查询没有安装的包,如果安装会安装的位置
d:查询系统文件属于哪个包
rpm -qf 系统文件名

2.1.6 启动httpd服务
service httpd start|stop|restart|status RedHat版本专有命令
/etc/rc.d/init.d/httpd start 标准启动
2.1.7 网页目录
/var/www/html
3、yum在线安装(前提条件能连网)
3.1 基本命令
yum -y install 包名 安装 -y 自动回答yes
yum -y remove 包名 卸载 当它不存在,不要乱卸载,不知道被谁依赖了,卸载一时爽,一直卸载一直爽,linux系统下再装回去一个软件可就要老命了
yum -y update 包名 升级
yum list 查询所有可以安装的包
3.2 光盘作为yum源

3.2.1 cd /etc/yum.repos.d/
默认网络yum源生效,在本机不能连网的时候让光盘yum源生效,网络yum源改名

3.2.2 mount /dev/sr0 /mnt/cdrom
3.2.3 vi /etc/yum.repos.d/
baseurl=file:///mnt/cdrom/ 指定yum源位置
enabled=1 yum源文件生效
gpgcheck=1 rpm验证不生效

本地光盘yum源起作用


pkill -9 yum-updatesd 如果yum报错正在升级,执行此命令,强制杀死升级进程
yum -y install gcc (gcc是C语言编译器,不装gcc,源码包不能安装,并且安装gcc只能rpm方式安装)
4、源码包安装
问题1:是否可以在一台电脑中既安装RPM包Apache,又安装源码包Apache?
答:可以,安装位置不一样,RPM包默认安装位置,源码包手工指定安装位置,一般 /usr/local/apache2/,只能启动一个80端口。
问题2:源码包和RPM包如何选择?
答:如果服务对大量客户端提供访问,建议用源码包,如果服务只给少数人访问,建议RPM包
问题3:源码包从哪里来?
答:官方网站下载
问题3:如何把windows文件拷贝到linux系统中?
答:1、远程传输工具winscp或者一些其他工具传输到linux
4.1 使用传输工具把源码包从windows传输到linux系统
4.2 安装
4.2.1 解压
4.2.2 cd 到解压目录

4.2.3 查看安装文档
INSTALL README
4.2.4 编译前的装备
./configure --prefix=/usr/local/apache2
功能:
1.检测系统环境 生成Makefile
2.定义软件选项

4.2.5 编译 make clean
make
4.2.6 编译安装 (在这一步之前报错只需要执行make clean就行,这一步报错需要make clean, 并且删除apache2目录重来)
make install
报错判断:
第一:安装过程是否停止
第二:注意 error warning no 等错误报警
4.3 启动
/usr/local/apache2/bin/apachectl start
4.4 删除
直接删除安装目录
RPM包和源码包的区别:
启动:
RPM包:service httpd start|stop|resrart
/etc/rc.d/init.d/httpd start
源码包: /usr/local/apache2/bin/apachectl start
网页:
RPM包: /var/www/html/
源码包: /usr/local/apache2/logs/
5.其他
5.1 date 查看系统时间

date -s 20130310 设定日期
date -s 16:20:00 设定时间
5.2 du -sh 目录名 统计目录大小(统计的文件大小是准确的,包括垃圾文件、缓存等)
-s 总和
-h 习惯单位

5.3 df -h 统计分区大小 (统计的分区剩余空间是准确的,统计硬盘容量)
【原创】 Vi编辑器

二、Vi编辑器使用
一、Vi编辑器简介
1、vim(vi增强版本) 全屏幕纯文本编辑器(只能写文字,写字符)
alias 起别名,临时生效,重启会消失

vi /root/.bashrc 环境变量配置文件
alias vi='vim'
二、使用vim
1、vi模式
vim 文件名

按一个字母a,光标会向后面退一格,进入到插入模式,按ESC退出插入模式;按一个字母i,光标在原来位置;按一个字母o,会换到下一行
命令--->输入 a追加,i:插入,o:打开(会向下换一行)
命令--->末行 :w(保存) :q(不保存退出) :wq(保存退出) !强制 :q!(任何用户都可以使用) :wq!(只有root用户才可以使用)
2、命令模式操作
2.1、光标移动 hjkl (依次左、下、上、右)
:n移动到第几行

gg 两个小写的'g'移动到整个文件首
G 大写'G'移动到整个文件尾
^ (shift+6) 或者Home 光标移动到行首
$ (shift+4) 或者End 光标移动到行尾
2.2、删除字母
x删除单个字母,nx删除n个字母
2.3、删除整行、剪切
dd删除单行
ndd删除多行
p 小p粘贴到光标后面
P(英文状态shift+p) 大P粘贴到光标前面

dG从光标所在删除到文件尾 (删除之后u撤销)
2.4、复制
yy 复制单行
nyy 复制多行
2.5、撤销
u 撤销
ctrl+r 反撤销
2.6、显示行号
:set nu 显示行号
:set nonu 不显示行号
2.7、颜色开关
:syntax off 关闭颜色
:syntax on 打开颜色
2.8、显示隐藏符号(非打印字符)
:set list 显示影藏字符
:set nolist 关闭隐藏字符

vi配置文件
~/.vimrc 手工建立的vi配置文件
~ 登录用的的家目录


2.9、查找内容
/搜索的字符内容 向下查找
n下一个 下一个 N(shift+n) 上一个 上一个
2.10、替换 s
^ 行首符
:1,10s/lg/leigong/g 替换1行到10行的所有lg为leigong
:%s/lg/leigong/g 替换整个文件的lg为leigong


g范围内替换所有,没有加g只替换找到的第一个,后面的就不会管了
:1,5s/^/#/g 注释1到5行
:1,5s/^#//g 取消注释
:1,5s/^/\/\//g 文件头加入//

【原创】 Linux常用命令

一、Linux常用命令
一、linux命令的格式
1、命令 [选项] [参数] (选项是调整命令的功能,参数是这个命令操作的对象)
ls -al anaconda-ks.cfg(参数) 文件、目录、进程可以作为参数
ls list 显示目录下内容
ls -a 显示所有文件(包含隐藏文件)
ls -al 长格式显示所有文件
ls -h 文件大小显示为常见大小单位 B KB MB
ls -d 显示目录本身,而不是里面的子文件
ls -i +文件名 显示文件的inode号

ls -l 长格式显示
-rw------- 1 root root 1190 08-10 23:37 anaconda-ks.cfg
第一项: 权限位
第二项: 1 引用计数(对没目录来说代表目录下的子目录,对文件没什么毛用)
第三项: root 所有者
第四项: root 属组
第五项: 大小
第六项 最后一次修改时间
第七项 文件名
2、提示符
[root@localhost src]#
[当前登录用户@主机名 当前所在目录]#
# 超级用户
$ 普通用户
用户家目录 管理员家目录 /root 普通用户家目录 /home/用户名
二、目录操作命令
1、cd 切换所在目录 列:cd /home
相对路径:参照当前所在目录,进行查找。一定要先确定当前所在目录。 root]#cd ../usr/local/src
绝对路径:cd /usr/local/src 从根目录开始指定,一级一级递归查找。在任何目录下,都能进入指定位置
cd 或者cd ~ 进入当前用户的家目录 超级用户 /root 普通用户 /home/aa/
cd - 进入上次目录
cd .. 进入上一级目录
cd . 进入当前目录
2、pwd 显示当前所在目录
3、linux常见目录
/ 根目录
/bin 命令保存目录(普通用户就可以读取的命令)
/boot 启动目录 ,启动相关文件
/dev 设备文件保存目录
/etc 配置文件保存目录
/home 普通用户的家目录
/lib 系统库保存目录
/mnt 系统挂载目录
/media 挂载目录
/root 超级用户的家目录
/tmp 临时目录
/sbin 命令保存目录(超级用户才能使用的目录)
/proc 直接写入内存的 (内存沾满之后会死机,重启会消失,不要随便动内存)
/sys 直接写入内存的
/usr 系统软件资源目录
/usr/bin/ 系统命令(普通用户)
/usr/sbin/ 系统命令(超级用户)
/var 系统相关文档内容
/var/log 系统日志位置
/var/spool/mail/ 系统默认邮箱位置
/var/lib/mysql/ 默认安装的musql库文件目录
4、建立目录
mkdir 目录名
mkdir -p 11/22/33 递归创建目录
5、删除目录
rmdir 目录名 (只能删除空目录)
rm 文件名 删除文件
rm -rf 目录 (删除文件和目录)
-r 递归 删除目录
-f 强制
6、tree 目录名 显示指定目录下所有内容的目录树
三、文件操作命令
1、创建空文件或修改文件时间
touch 文件名
2、删除文件
rm -rf 文件名
-r 删除目录
-f 强制
3、cat 文件名 查看文件内容;从头到尾
cat -n 文件名 列出行号
空格向下翻页,b向上翻页,q退出
linux本机 shift+PageUp 向上翻页,shift+PageDown 向下翻页
4、more 文件名 分屏显示文件内容
5、head 文件名 显示文件头
head -n 行数 文件名 显示指定文件头几行
head -n 20 test1 显示文件头20行
head -20 test1 显示文件头20行
6、tail 文件名 显示文件尾
tail -f 文件名 监听文件尾,不退出
快捷键
ctrl + c 强制终止
ctrl + l 清屏
ctrl + u 光标所在删除到行首
ctrl + y 粘贴删除的内容
ctrl + a 光标移动到行首
ctrl + e 光标移动到行尾
7、链接文件(类似于windows的快捷方式)
ln -s 原文件 目标文件 文件名都必须写绝对路径
ln -s /root/mymulu/test1 /tmp/bols

更改原文件软链接数据也更改,更改软链接原文件数据也一样更改,删除原文件软链接打不开,删除软链接原文件不影响。

四、文件和目录都能操作的命令
1、rm删除 删除文件或目录
2、cp复制
cp 原文件 目标位置
-r 复制目录
-p 连带文件属性复制
-d 若原文件是链接文件,则复制链接属性
-a 相当于 -pdr
cp -a /root/mymulu/test2 /tmp/t2
3、mv 剪切或改名
mv 原文件 目标位置
mv /root/mymulu /tmp/mymulu 剪切
mv /root/mymulu /root/my1 原文件位置和目标文件位置在同一个目录下就是改名
五、权限管理
1、权限位
-rw-r--r--. 1 root root 11 Mar 2 13:36 test2
权限位十位:
第一位:文件类型,(- 普通文件;d 目录文件;l 链接文件;c 设备字符文件 )
第二位到第十位(共九位权限位)
九位 属主权限u(user) 属组权限g(group) 其他人权限o(other)
r 读 4
w 写 2
x 执行 1

2、chmod 修改权限
chmod u+x test1 test1文件的属主加上执行权限
chmod u-x test1
chmod g+w ,o+w test1
chmod u=rwx test1
chmod 755 test1
chmod 644 test1
777 绝对不允许在服务器给目录赋予777权限
3、权限的意义
3.1、权限对文件的含义
r:读取文件内容 对应命令: cat more head tail
w:编辑、新增、修改文件内容(不包含删除文件内容) 对应命令: vi、echo
x:可执行 对文件来说最高权限是执行权限
给hello.sh文件赋予755权限,并且执行它

执行文件两种方式,1、绝对路径方式 2、相对路径方式

3.2、权限对目录的含义
r:可以查询目录下文件名 对应命令:ls
w:具有修改目录结构的权限。如新建文件和目录,删除此目录下得文件和目录,重命名此目录下得文件和目录,剪切, 对应命令:touch rm mv cp ,对目录来说最高权限是写权限
x:可以进入目录 对应命令:cd
目录可用权限: (必须要有查看权限和进入目录权限)
0 最小权限
5 基本权限
7 最大权限
4、属主和属组命令 chown
chown 用户名 文件名 改变文件属主
chown user1 aa1 user1用户必须存在
chown user1:user1 aa1 改变属主的同时改变属组
useradd 用户名 添加用户 (在添加用户的时候默认会添加一个和用户名一样的组)
passwd 用户名 设定用户密码
六、帮助命令
1、man 命令 查看命令的帮助
man ls
2、命令 --help
touch --help 查看命令的常见选项
七、查找命令
1、whereis 命令名 查找命令的命令,同时看到帮助文档的位置
它在哪?

它是干嘛的

2、find 搜索命令
按照“文件名”查找 -name
find 查找位置 选项 文件名
find / -name abc 按照文件名查找


按照“用户”查找 -user
find . -user root 查找当前目录所有者是root的文件
find . -group root 查找当前目录所属组是root的文件
find / -nouser 查找/目录下没有属主的文件
Linux中没有所有者的文件,以下两种是正常的:
1、外来文件(U盘、光盘)
2、极少内核产生的文件
/proc /sys /mnt/cdrom/ 除了这三个目录
通配符:
* 匹配任意内容
? 匹配任意一个内容
[] 匹配任意一个中括号里面的内容
正则:
* 前一个字符匹配任意多次
. 匹配任意一个字符
.* 匹配任意内容
? 前一个字符匹配0次或1次
[] 匹配中括号内任意一个字符
通配符:用来匹配查找文件名,通配符是完全匹配,必须一模一样(用来匹配字符串),完全匹配(find查找)
正则: 用来匹配文件里的内容,是包含匹配(grep查找)
按照“文件大小”查找 -size
-size 按照文件大小查找 +50k,大于50k,-50k,小于50k,50k,等于50k k(千字节必须小写),M(兆字节必须大写)
-size n[cwbkMG](选项)
File uses n units of space. The following suffixes can be used: 文件使用n个空间单位。可以使用以下后缀:
‘b’ for 512-byte blocks (this is the default if no suffix is used) b是选项默认的,不加单位则按照512字节作为一个数据块搜索
‘c’ for bytes 按照字节搜索

‘w’ for two-byte words 双字节,按照一个字搜索
‘k’ for Kilobytes (units of 1024 bytes) “k”表示千字节(1024字节的单位)按照千字节搜索
‘M’ for Megabytes (units of 1048576 bytes) “M”表示兆字节(单位为1048576字节)按照兆字节搜索
‘G’ for Gigabytes (units of 1073741824 bytes) “G”表示千兆字节(单位为1073741824字节)按照千兆字节搜索
find . -size -1k 在当前目录查找小于1k字节的文件

按照“文件类型”查找 -type
-type 类型 按照文件类型查找 f:普通文件 d:目录 l:链接文件
find . -type f
find . -type d
按照“权限”查找 -perm
find . -perm 644
按照“文件名不区分大小写”查找 -iname
find . -iname abc

按照“i接点”查找 -inum
find . -inum 786119 知道i节点去查找文件名

ls -i 知道文件名去查找i节点

按照“修改时间”查找 -mtime
-10,10天内;+10,10天前;10,第10天
在查找出的结果中,直接进行命令操作

长格式显示1天内m2目录下面创建的文件和目录

3、grep "字符串" 文件名 查找符合条件的字串
grep "root" /etc/passwd
grep -v "root" /etc/passwd -v反向选择(取反),在/etc/passwd 中不存在root 字符的
4、管道符
命令1 | 命令2 命令1的执行结果作为命令2的执行条件 (管道符的作用和-exec的作用一模一样,find命令不支持管道符,所以专门开发了-exec命令)
只要加了管道符,不论前面是文件还是内容,全都当做文件内容来处理,使用grep搜索查找
netstat -an | grep ESTABLISHED | wc -l 统计正在连接服务器的网络连接数量
补充命令:
netstat 查看网络状态的命令
-t 查看tcp端口 (tcp通信,需要进行三步,A问B你在吗,B答复A我在,A再给B回复我要发数据了,可靠)
-u 查看udp端口 (udp,A直接发数据给B,速度快)
-l 监听
-n 以IP和端口号显示,不用域名和服务名显示
netstat -tuln 查看本机开启的服务

netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n 按照连接数量,统计哪个ip地址连接数量多,可以用来屏蔽排除非法攻击
八、压缩和解压缩
1、linux可以识别的常见压缩格式
.gz .bz2
2、常见的压缩和打包命令
.tar.gz (压缩性能相对较差,但是速度更快) .tar.bz2 (算法先进,压缩出来结果更小,但是更占用时间)
linux不靠扩展名区分文件类型,而是靠权限,建议linux系统下压缩包严格区分扩展名
tar -zcvf 压缩文件名 源文件
tar -zcvf aa.tar.gz aa
-z 识别.gz格式
-j 识别.bz2格式
-c 压缩
-x 解压缩
-v 显示压缩过程
-f 指定压缩包名
-t 只查看不解压
查看不解包
tar -ztvf aa.tar.gz 查看不解包
tar -jtvf aa.tar.bz2
指定到解压位置
tar -jxvf aa.tar.bz2 -C /tmp/
九、关闭和重启命令
服务器绝对不允许关机,只能重启,并且服务器应该定时重启,保证服务器状态归零
1、shutdown -h now 没有特殊情况,禁止使用此命令
shutdown -h 关机
shutdown -r now 立即重启 (shutdown -r 重启,最安全的重启命令,会保存正在运行的服务然后再重启)
shutdown -r 16:00 16:00重启 -r(reboot)
windows设置关机,shutdown -s -t 200(秒)
2、reboot 重启
十、挂载命令
linux所有存储设备都必须挂载使用,包括硬盘
挂载:给你的分区找到一个硬件名,创建一个目录,把它连起来
/dev/sr0<------->cdrom
1、mount 挂载
mount -t 文件系统 设备描述文件 挂载点(已经存在的空目录)
mount -t iso9660 /dev/sr0 /mnt/cdrom/ 默认挂载选项
mount /dev/sr0 /mnt/cdrom/ 简写挂载
光盘挂载
/dev/sda1 第一个scsi硬盘的第一个分区
/dev/cdrom 光盘
/dev/hdc 光盘 centos5.5
/dev/sr0 光盘 centos6.x

/dev/sr0 设备文件名 /mnt/cdrom/ 才是盘符
mount直接回车,查看当前已经挂载的设备
2、umount 卸载
umount /mnt/cdrom 强调:退出挂载目录,才能卸载
十一、网络命令
1、ping 测试网络连通性
ping -c 次数 ip 探测网络通畅

2、ifconfig 查询本机网络信息

Linux脚本中 #是注释 唯独一句 #!/bin/bsah 不是注释, 标注下面是shell语句开始...
十二、centOs7防火墙操作命令
1、防火墙开启、关闭、禁用
(1)设置开机启用防火墙:systemctl enable firewalld.service
(2)设置开机禁用防火墙:systemctl disable firewalld.service
(3)启动防火墙:systemctl start firewalld
(4)关闭防火墙:systemctl stop firewalld
(5)检查防火墙状态:systemctl status firewalld
2、使用firewall-cmd 配置端口
(1)查看防火墙状态:firewall-cmd --state
(2)重新加载配置:firewall-cmd --reload
(3)查看开放的端口:firewall-cmd --list-ports
(4)开启防火墙端口:firewall-cmd --zone=public --add-port=9200/tcp --permanent
命令含义:
–zone #作用域
–add-port=9200/tcp #添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
注意:添加端口后,必须用命令firewall-cmd --reload重新加载一遍才会生效
(5)关闭防火墙端口:firewall-cmd --zone=public --remove-port=9200/tcp --permanent
【原创】 寻找天赋
寻找天赋
核心天赋藏在自己所厌恶的缺点中,能赚到钱的本事藏在天赋里
一、回想自己从小到大被人批评最多的缺点是什么,也可以是自己内心深处最讨厌的行为,然后记下来
① 优柔寡断,选择困难。
② 独立不合群。
③ 不自信,在人多的场合没胆量,放不开。
④ 厌恶脾气臭,讨厌恶毒脏话。
⑤ 专注度不强,看书容易走神,照照镜子,刷刷抖音,拔拔胡子,挤挤痘痘。
⑥ 虚伪、不够真诚
⑦ 冷漠、不近人情
⑧ 多疑
⑨ 懦弱、胆小怕事
二、把这些缺点翻译成意思相同但是好听的词句,就是往好听的说
① 思虑周全,尊重每一种可能性;行事稳重,不草率下结论。
② 享受独处,是因为灵魂自有共鸣,具有独立思考问题的能力。
③ 在人群之中,习惯于先做一位深情的聆听者;内敛不是短板,而是一种未被完全解读的深度。
④ 偏爱言语间的兰香,难以忍受唇齿间的戾气;心中无戾气,耳畔自清音;言语即修行,只与温柔共振;近善言,远恶语。
⑤ 看书看久了,灵魂会偷偷溜出去照照镜子;在文字的海里游累了,便上岸修修边幅,逗逗时光。
⑥ 处事圆融,懂得在不同场合调整表达方式;善于保护隐私。情绪稳定,冷静理智;不随意消耗能量,只对值得的人热情。
⑦ 情绪稳定,冷静理智;不随意消耗能量,对值得的人热情。
⑧ 警惕性高,有危机意识;思虑周全,不容易上当受骗。
⑨ 行事谨慎,懂得避其锋芒;热爱和平,不惹是非。
三、在生活中留意自己的缺点在什么场景下是缺点,什么场景下是优点,然后在是优点的场景下把自己的天赋兑换成财富
优点场景:
① 在办公室安静的敲代码
② 阅读财经新闻,阅读国家政策,分析市场行业,分析企业生意模式,阅读企业财报。
四、获得自信
自信,和人的语言能力关系非常大,能不能把一件事情往好听的说, 能不能把一件事情往不好听的说,一个不自信的人往往缺乏这种语言翻译能力,而自信的人特别擅长这种翻译。
① 事物都有两面性,灵活的转化让自己永远不处于不利的那一面,就会很自信。人之所以不自信,就是别人给自己一个负面标签评价或者自己给自己一个负面标签评价,没有能力把这种负面评价转换成有利的说法。
② 事实对我们有利的时候就强调事实,规则对我们有利时就强调规则。处理事情的思维不要永远都得讲道理,但也不能完全不讲道理,如果万事能讲道理谈得通,从古至今也不会有土匪、强盗、军队了。(曹贼:喜欢别人的老婆 转化:喜欢的人成了别人的老婆)
【原创】 投资一家公司多维度思考

投资一家公司多维度思考
投资企业前的挥杆分析
1、天山铝业
① 文化(口号) 企业文化合格√
企业价值观:激情 高效 关爱
工作重心:安全环保
公司使命: 让地球更加轻盈,更美丽
企业愿景:共建长青一流企业
经营理念:社会、企业、个人的目标、责任、利益相统一
② 行动
待观察,途径:官网、公众号、新闻、社会活动等等...
③ 护城河:品牌一般、技术在行业中中规中矩、铝锭产品在行业中不具有差异化 护城河一般 ×
④ 商业模式:能产生持续充沛的自由现金流,铝锭价格并非单纯由期货决定,而是形成了一个以期货市场为“定价中枢”和“指挥棒”,现货市场为“基本面验证者”的紧密联动体系(铝锭价格主导力量:期货交易所 重要参与者影响:大型生产商、大型贸易商、终端消费、金融机构与投资者、政府与监管机构、国际环境因素、国际金属价格趋势等),且天山铝业属于重资产类型企业,具有持续资本性开支来维持在行业中的地位 商业模式一般 ×
⑤ 估值 (前提是选择一个护城河优秀、商业模式好的企业,上述天山企业只能说一般) 估值5年内翻倍,估值一般 ×
思路: 根据2025年三季报作为参考,毛估估:
a:确定当前自由现金流
经营活动产生的现金流净额(所有者盈余):48.5Y
资本性支出:11.4Y
自由现金流:经营活动产生的现金流净额 - 资本性支出 48.5-11.4 = 37.1Y
b:估算一个保守增长率 未来5年,给一个6%
c:估算第一阶段现金流现值
1年后的现金流 ≈ 37.1* (1.06)^1 ≈ 39.32亿元。
2年后的现金流 ≈ 37.1* (1.06)^2 ≈ 41.68亿元。
3年后的现金流 ≈ 37.1* (1.06)^3 ≈ 44.18亿元。
4年后的现金流 ≈ 37.1* (1.06)^4 ≈ 46.83亿元。
5年后的现金流 ≈ 37.1* (1.06)^5 ≈ 49.64亿元。
d:确定折现率: 长期国债利率 2.3% ~~2.5%, 我们取一个5%--10%的区间值 5%作为折现率
e:估算永续价值
① 假设永续价值为0
② 永续价值 = 第N年的自由现金流 / 折现率 49.64 / 0.05 ≈ 992.8
③ 毛估估总内在价值 = 永续价值 + 第一阶段现金流现值 992.8 + 39+41+44+46+49 ≈ 1211.8 Y
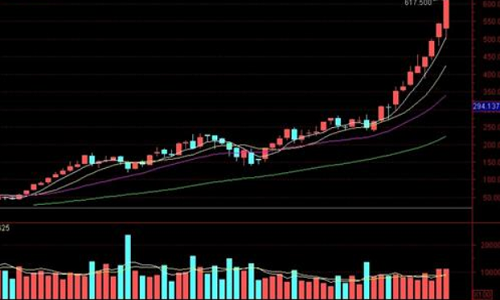
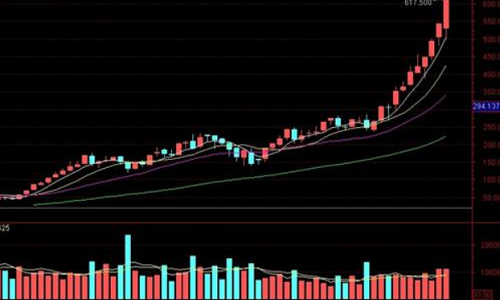
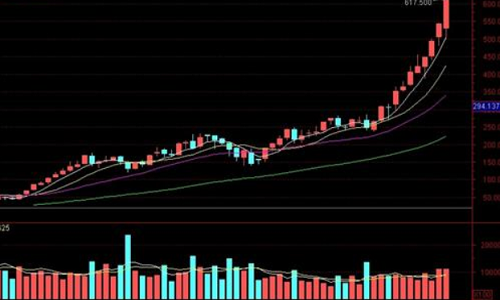
结论:天山铝业目前市值650Y,5年内保持年6%以上的净利润增长率,5年内的某个时间节点有几率市值达到1200Y, 通过以上5个方面要素分析,天山铝业 1 √ 3× 1待观察不确定, 不是最佳投资选择,继续分析其他目标
【原创】 十七、十五五及未来5-10年风口行业
十五五及未来5-10年风口行业
一、十五五规划风口行业总结
1、待补充
二、未来5-10年风口行业
1、银发经济与大健康 (养老护理、高端养老社区、陪护机器人,60岁以上人口近3亿,健康监测设备需求激增) √
2、集成电路/芯片 加速迭代 √
3、人工智能 加速迭代,融合应用 (细分领域:AI芯片、端侧AI硬件设备、垂直领域大模型、行业应用软件) √
4、量子科技
5、生物制造/脑机接口
6、氢能/核聚变能
7、第六代移动通信
8、高端制造硬科技 (细分领域:人形机器人、高阶智驾) √
9、低空经济与商业航天 (空域开放,低空经济商业化 细分领域: 无人机物流、eVTOL载人出行、卫星互联网) √
10、数字经济与数据要素
【原创】 基础知识

基础知识
一、未来十年贬值最快的是什么
①大学文凭(学历),就业市场学历通胀。
②非核心城市房产,人口老龄化+生育率下降,三四线城市空置率攀升,房价持续下跌
③传统燃油汽车
④现金、存款,全球低利率环境延续,存款利率持续下行; 人民币国际化进程中可能面临汇率波动风险,进一步影响储蓄价值。
⑤奢侈品
⑥A股股票,新股发行速度过快导致资金分流,估值泡沫风险高;投资者结构以散户为主,投机性强,长期投资价值不足。
⑦传统世俗文化观念,年轻人对婚姻、家庭的传统观念淡化,晚婚、不婚、丁克等;节日习俗、宗族观念逐渐被个性化生活方式取代。
⑧低技能重复性工作岗位,自动化和AI技术普及,工厂普通岗位需求锐减。
⑨中产阶级身份象征,象征地位的物品(名牌包、高档轿车等)大众化而失去独特性。
①①燃油车相关产业,如加油站、零部件等。
【原创】 莫生气

莫生气
2024-7-15笔记:
①一切的不快皆源于心态,有什么样的心态,就会有什么样的生活。
②心态是快乐的,我们自然就是快乐的;如果满脑子忧郁的想法,就会显得十分悲观。
③令自己灰心丧气的不是所遭遇的各种状况,而是你对这些状况的想法。
④很多时候快乐其实是内心的富足,与金$无关。
⑤想活得轻松一些,就要凡事豁达一点、洒脱一点,不必把一点点小惠小利看得过重,而要达到这种超脱境界,关键是寻求心灵的满足。
2024-7-16笔记:
①乐观的人并不是生活上万事如意,而是他们明白,能够战胜困难的永远不会是沮丧忧愁,而是勇敢与微笑。
②逃出自筑的精神牢狱,寻找满天繁星。
③快乐源自于一种成就感,一种自我超越的胜利。
④生命是一个自然的过程,生的必然和死的必然都是一样的。春天,百花盛开,树木抽芽,到了秋天,树叶飘落,乃至草木枯萎,这就是无常相。
⑤忘掉过往,它会遮蔽未来。
⑥要想成为一个幸福的人,必须先敞开你的心扉。
⑦无论遭遇什么困难,只要你不顾一切的去拥抱生活、寻求快乐就能从痛苦中解脱。也只有乐观向上的人,才能理解和享受生活。
⑧事实上,幸福是无所不在的,“保持高度的幽默感”是关键之一。
2024-7-17笔记:
①人之所以活得累,是因为放不下架子,撕不开面子,解不开情结。
②不去勉强别人,也不强求自己。
③既不感叹命运也不抱怨时代,当不了大树就当小草,当不了太阳就当星星,当不了江河就当小溪。
④世间没有什么东西是恒久不变的。
⑤一个人的智力有问题,是次品;一个人的灵魂有问题,就是危险品。
⑥你是积极的,世界就是积极的。反之亦然,这就是观念的力量。
⑦只有当你心中的世界模式发生了改变时,现实的世界才会随之改变,使你适应并与之达到和谐。
⑧如果我们用一种忧郁的心态面对人生,那么,人生就会成为一种折磨和煎熬。
2024-7-19笔记:
①生气是人生幸福的最大障碍之一,是事业成功的拦路虎。
②通常,易发脾气的人与人相处尝尝出言不逊,不顾他人的自尊心与个性特点,一味强求别人与自己保持统一,这样的人很难获得和谐的人际关系。
③动不动就生气的人,往往什么事都办不成,因为满怀怒气,必然丧失理智。
④遇到麻烦不要抱怨也不要责怪他人,带着神么样的态度去处理问题就注定了会得到什么样的结果,控制好情绪让自己平静,努力想最优的解决办法去处理问题。
2024-7-27笔记:
①托人办事,首先礼貌问候、寒暄,如果合适,适当礼物。
②在①得到良好回应后再引出自己的需求,需要的帮忙。
2024-8-8笔记:
①安身立命谨记16字:藏锋、隐智、戒欲、省身、求实、慎言、节情、向善
藏锋:才华不外露。
隐智:不露才智。
戒欲:戒欲是指对欲望或冲动的抑制或控制,通常用于描述对一些负面或有害的欲望或冲动进行抑制或限制的过程。
省身:字面意思是检查自身过失,克制自己非分之想。在更深层次的理解上,省身强调的是在日常生活中随时随地对自身行为进行反省与自律的一种状态。这一概念源于儒家思想,特别是曾子所说的“吾日三省吾身”,即每天多次自我反省。省身不仅是自我检查行为的对错,更是对内在思想的自省和外在行为的检点,是修身养德的基础。
求实:指讲求实际,客观地或冷静地观察以求得对客观实际的正确认识。这一概念强调了在实际行动和决策中基于事实和实际情况的必要性。
慎言:说话非常谨慎。
节情:学会控制情感,避免过度悲伤,保持平静和乐观。它强调在情感的表达上要适度,既不压抑也不放纵,以实现内心的和谐与平衡。节情不仅是对内心情感的深思熟虑和精准把控,更是一种高超的自我调控艺术,旨在增进人与人之间的理解和沟通。
向善:字面上理解,就是向着善良的方向行动。它强调的是一种积极向上的行为准则,即通过自己的行为去帮助他人,做对他人有益的事情。这种行为不仅体现了个人对他人的关爱和帮助,也反映了个人内心的善良和积极向上的态度。
2024-8-19笔记:
①做人第1点:坚持原则,坚持底线,坚持初衷。《道德经》中有言“持而盈之,不如其已;揣而锐之,不可长保。金玉满堂,莫之能守;富贵而骄,自遗其咎。功成身退,天之道也。” 做人不能抛弃、不能践踏信用和原则。
②做人第2点:一定要懂礼貌,学习礼仪,学习历史文化。
③做人第3点:看书,坚持学习,有一句话是那么说的,一个人如果长期不看书,那么他的人生观将由他身边的人决定。
【原创】 父母的寄托

父母的寄托
青春期以及年轻时候我很倔强,很不听话,现在年龄来到三十多岁,老妈分享一些视频给我,看完我也会哭,她头发已经花白,60岁左右的人了,而我也马上进入中年,且一无所有,每当看到这类的视频感触颇深。感触可能会在短暂的瞬间触动很深,过后可能逐渐被日复一日的忙碌磨灭。感谢各位作者老师,我搬来了你们的金石良言,时常来接受灵魂的触动。
五六年的码农生涯,变得越来越自闭,不善于交流和表达感情,就记在这里吧,没地方表达。
看多了几次下面两个视频,眼泪鼻涕流了十几分钟没停止 ----2024-5-30 23:39:18
① 孩子,是父母唯一的寄托。
② 我不能走,我走了以后我的孩子怎么办。
③ 不要等到父母不在的时候再后悔,为时已晚,人活着的时候不孝顺,等到父母没了,去坟前烧香烧纸那都是骗人的。
④ 不能像个废物一样活着,不允许,不管现在身处在什么样的群体阶层,坚持学习坚持看书,不看书,价值观将由身边的人决定。
----------分割线----------
【原创】 十一、怎么买会赔钱

怎么买(操作)会赔钱
一、记录赔钱的操作!!!
1、迫切的想把今天账户做红,接受不了账户绿色,被市场情绪带崩、主力洗盘恐吓,由红到绿跌破0轴水下割肉,最无语的是下午拉回0轴再水上追高,典型追涨杀跌。
2、连续回调不建仓,连续涨幅以后追进去。
3、做短线、做题材、做热门,跟随市场情绪投机买卖。
4、打野,价值投资遇到连续几天回调,外面市场涨得五彩缤纷就开始动摇割肉出去追短线。
5、对一只股没有下足够的功课,没有看清公司的生意,没有看清股票的估值是否过高,没有看清楚公司未来赚取现金流的能力,甚至根本没有花多少时间分析只是观察了K线图形,主观臆想有机会就随意买进。
6、没有仔细分析产品的应用领域及下游的需求量,没有认真读财报,认知不到位,看不懂所以拿不住,拿得住的前提是看得懂,看懂了才有信心(新易盛)。
【原创】 HTTP状态码

HTTP状态码
一、常用状态码
1. 100 开头状态码

2. 200 开头状态码


3. 300 开头状态码


4. 400 开头状态码

5. 500 开头状态码


【原创】 Redis应用

Reids + PHP应用
一、消息队列原理、概念
1.1 消息队列概念
a、队列结构的中间件
b、消息放入后不需要立即处理
c、由订阅者/消费者按照顺序处理
1.2 核心结构

1.3 应用场景
冗余:比如订单系统,需要严格的做数据转换和记录,消息队列可以持久化的把这些信息存储在消息队列中
解耦:比如两套系统,彼此独立
流量削峰:秒杀和抢购,配合缓存来使用消息队列
异步通信:
排序保证:
1.4 常见队列实现优缺点
队列介质:

1.5 消息处理触发机制

二、解耦案例-队列处理订单系统和配送系统
2.1 架构设计

2.2 程序流程

三、流量削峰案例 - Redis的List类型实现秒杀
3.1 架构设计

3.2 代码设计

用户秒杀的代码


模拟秒杀生成的uid参数

读取redis队列,数据写进数据库的代码


四、RabbitMQ - 更专业的消息系统实现方案
4.1 RabbitMQ的架构和原理

4.2 RabbitMQ安装

4.3 Work Queue

五、PHP秒杀系统整体设计
5.1 本质
高并发、高可用
5.2 原理知识介绍
减而治之:
a、CND原理
b、nginx限流
c、异步队列
分而治之:
a、nginx负载均衡
5.3 特征与难点分析
特征:
a、写强一致性:卖出的商品、计数的数量一致
b、读弱一致性:比如12306抢票的时候确实看到有票,下单的时候却没了
难点:
a、极致性能的实现
b、高可用的保证
5.4 秒杀系统核心实现
1. 极致性能的读服务实现:
a场景、订单详情页读取,通过CDN加速方式减轻服务器压力
b场景、实时读取总库存
2. 极致性能的写服务实现:
a场景:扣库存
3. 极致性能的排队进度查询实现
比如12306抢票,可能会有一个排队的进度,用户频繁去查询还剩多少分钟,这么一个服务
4. 链路流量如何优化
比如流量到达LVS层、接入层、service层
5.5 兜底-高可用
1. 高可用的标准
2. 请求链路中每层高可用的实现原理
3. 限流、一键降级、自动降级实现
5.6 接口压力测试
平时使用最多的ab压测工具,通过 “Requests per second:”这一项数据值分析接口和机器性能状态
5.7 限流
1. nginx限流配置

区别:上面一个限制并发数,下面一个限制单个ip请求数

2. 限流算法介绍
a、令牌桶算法



b、漏桶算法


5.8 CND介绍

提高读源站性能一大利器
CND原理:


CDN - 普通域名访问

CDN - DNS解析原理




注意:不同地域的客户端访问同一个域名的时候,拿到的CND地址是不一样的,基本是距离客户端比较近的CDN服务器地址,通过这样的方式来实现一定的加速;而CDN服务器也会把源站上的内容做一定时间的缓存,通过这样的方式来降低源服务的qps,提高读服务性能
5.9 大型网站架构

5.10 秒杀系统使用场景

5.10.1 秒杀系统 - 特点介绍
a、抢购人数远远多于库存,读写并发极大
b、库存少,有效写少
c、写强一致性,商品不能超卖,也就是说库存减少量与创建订单量必须一致的
d、读一致性要求并不高
5.10.2 秒杀系统 - 难点
稳定性难:
a、高并发下,某个小依赖可能直接造成雪崩
b、流量预期难精确,过高也会造成雪崩
c、分布式集群,机器多,出故障的概率高
准确性难:
a、库存、抢购成功数、创建订单数之间一致性
高性能难:
a、有限成本下需要做到极致的性能
5.10.3 秒杀系统 - 架构原则
稳定性:

高性能:

5.11 秒杀服务核心实现
5.11.1 该怎样去设计?

基本需求:

基本需求 - 场景举例:

基本需求 - 扣库存方案:

预扣库存方案实现:

极高并发下怎么做到单服务极致性能:

I/O主要包含:

无I/O怎么做?

普通下单业务实现:

去I/O后的业务实现:

并发量过大单服务还是扛不住怎么办?

本地减库存,集群机器挂了怎么办?怎么保证不少卖?

单服务扣库存实现:
1、初始化库存到本地库存
2、本地减库存,成功则进行统一减库存,失败则返回
3、统一减库存成功则写入mysql,异步创建订单
4、告知用户抢购成功
创建订单、支付订单服务:

基本需求 - 读取商品信息:

【原创】 电脑装杯小技巧

常用装杯小技巧
装杯技巧记录
1、快速回到桌面:
Windows + D
2、一键锁屏:
Windows + L
3、快速打开文件资源管理器:
Windows + E
4、快速放大文字或者图片:
Windows + “+”
5、快速缩小文字或者图片:
Windows + “-”
6、隐藏打开的窗口文件:
Windows + M
7、快速打开任务管理器:
Ctrl + Shift + Esc
8、快速打开Windows设置:
Windows + I
9、恢复上一步操作:
Windows + Y
【原创】 二、PC端工具快捷键

通达信快捷键使用
1、第一类 数字类
03回车,调出沪指
04回车,调出深成指
06回车,调出自选股
09回车,画线工具
15回车,板块指数
45回车,显示未回补跳空缺口
48回车,显示最近浏览的股
50回车,上证50走势
60回车,当天的实时涨跌幅排名
80 回车,综合排名,查看当天市场跌幅、振幅、涨幅等排名
880005 涨跌家数
2、第二类 字母类或者组合类
Table,关闭/显示均线
F1,表格形式查看个股每天的情况
F5,查看分时图
F6,查看自选股
F8,切换周期(5分钟、30分钟、日K等)
F10,查看个股信息
ctrl+R,个股题材概念、板块信息等
ctrl+K ,前复权/不复权
ctrl+L ,显示隐藏行情信息(右边买卖、市值、个股名称等等)
3、第三类 字符数字组合类
.400 板块分析-所有版块
.403 区间涨跌幅
.404 区间换手排名
.403 区间涨跌幅
.5/.501 分时走势图
.502 分时成交明细
.503 分价表
4、第四类 K线类
平移K线 分析图主图中左键拖拽屏幕底部时间标尺
压缩K线 分析图主图中右键拖拽屏幕底部时间标尺
缩放K线 分析图中Ctrl + 鼠标滚轮
【原创】 Redis入门、第二部分

Reids数据库基础知识
一、Redis高级
1.1 通用命令
1.1.1、key通用指令
key特征:key是一个字符串,通过key获取redis中保存的数据
key应该设计哪些操作?
对于key自身的状态相关操作,例如:删除,判定存在,获取类型等
对于key有效性相关操作,例如:有效期设定,判定是否有效,有效状态的切换等
对于key快速查询操作,例如:按指定策略查询key
key基本操作:
a、删除指定key:del key

b、获取key是否存在:exists key

c、获取key的类型:type key

key扩展操作(时效性):
a、为指定key设置有效期:expire key seconds

b、为指定key设置有效期:pexpire key milliseconds

c、为指定key设置有效期:expireat key timestamp

d、为指定key设置有效期:pexpireat key milliseconds-timestamp
e、获取key的有效时间:ttl key

ttl获取key过期时间,如果一个key不存在,则返回-2;如果一个key存在,则返回-1;如果一个设置了有效期,则返回剩余有效时间
f、获取key的有效时间:pttl key

g、切换key从时效性转换为永久性:persist key

key通用操作:
a、查询key:keys pattern(匹配的语法格式)




key其他操作:
a、为key改名:rename key newkey

b、如果key不存在则为key改名:renamenx key newkey
![]()

c、对所有key排序,只是排了序,没有动原来数据:sort key

1.2 数据库通用指令
1.2.1、看如下问题

1.2.2、db基本操作
a、切换数据库:select index

b、控制台打印:echo xxx

c、测试客户端与服务端连通性:ping

d、移动数据:move key db

数据清除操作(谨慎、小心操作):
e、清除当前数据库:flushdb
f、清除所有数据库:flushall 不要用这个指令,0-15号库数据全部干掉...
g、查看数据容量:dbsize

二、Redis持久化
2.1 意外的断电

2.2 自动备份

2.3 什么是持久化
利用永久性存储介质将数据进行保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化
2.4 为什么要持久化
防止数据的意外丢失,确保数据的安全性
2.5 持久化过程保存什么

2.6 持久化方案一 ,RDB启动方式--save指令

持久化的命令:save
作用:手动执行一次,保存一次

2.6.1 RDB相关配置
RDB启动方式----save指令相关配置

1、设置dbfilename

2、设置rdbcompression 值为yes

2.6.2 数据恢复过程演示

杀掉进程后再启动,上图的3420进程,redis又重新运行

数据已经恢复

2.6.3 save指令工作原理
1、假如4个指令都要执行,并且按照客户端1--4的顺序先后到达并执行

2、到达以后假如是下面的指令排序

3、指令执行

4、save指令有可能造成阻塞,拉低服务器性能,线上环境不建议使用save指令

2.7 持久化方案二 ,RDB启动方式--bgsave指令
数据量过大,单线程方式造成效率过低如何处理?

2.7.1 持久化命令
指令:bgsave
作用:手动启动后台保存操作,但不是立即执行
操作:

执行bgsave命令前

执行bgsave命令后,文件大小已经变了

查看文件内容,已经增加了addr值chengdu

2.7.2 bgsave指令工作原理
1、下达指令

2、调用linux的fork函数,生成子进程,由子进程去完成

在日志文件去查看这个过程

注意:bgsave命令是针对save命令阻塞问题做的优化,save命令是立马执行,并且加入到任务执行序列中,bgsave采用的是fork创建的子进程来完成的这个过程;redis内部所有涉及到RDB操作都采用bgsave方式,save命令可以放弃使用
2.7.3 bgsave指令相关配置


2.8 持久化方案三 ,RDB启动方式--自动执行

2.8.1 配置
指令配置:save second changes
作用:满足限定时间范围内key的变化数量达到指定数量即进行持久化
参数:second -- 监控时间范围 changes -- 监控key的变化
位置:在conf文件中进行配置,不要乱设置,设置不合理也是灾难性的;second和changes一般遵循前面大后面小,前面小后面大

范例:

注意:只要是在设定的时间范围内,满足条件的key数量发生变化(包括添加、修改),就会自动保存数据
2.8.2 RDB启动方式save配置原理

2.9 RDB三种启动方式对比

![]()

2.10 RDB特殊启动方式

2.11 RDB的优点与缺点

2.12 AOF简介
RDB的弊端:
1、存储数据量较大,效率较低,基于快照的思想,每次读写都是全部数据,当数据量巨大时,侠侣非常低
2、大数据量下的IO性能较低
3、基于fork创建子进程,内存产生额外消耗
4、宕机带来的数据丢失,快照思想存储是基于某个时间点的数据,无法做到即时的数据存储
解决思路:
1、不写全数据,仅记录部分数据
2、改记录数据为记录操作过程
3、对所有操作均进行记录,排除丢失数据的风险
AOF概念:
1、AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的,与RDB相比,可以简单的描述为:改记录数据为记录数据产生的过程
2、AOF主要作用是解决了数据持久化的实时性,目前已经是redis持久化的主流方式,优先使用AOF方式
2.13 AOF写数据过程

2.14 AOF写数据的三种策略

2.15 AOF功能开启
配置:appendonly yes|no,默认是no
作用:是否开启AOF持久化功能,默认为不开启状态

配置AOF策略:appendfsync always | everysec | no
作用:AOF写数据策略

案例演示:



AOF其它相关配置:

2.16 AOF写数据遇到的问题

AOF重写:
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,redis引入了AOF重写机制压缩文件体积。AOF文件重写是将redis进程内的数据转化为写命令同步到新AOF文件的过程。简单说就是将对同一个数据的若干个命令执行结果转化成最终结果数据对应的指令进行记录
AOF重写的作用:
降低磁盘占用量,提高磁盘利用率
提高持久化效率,降低持久化写时间,提高IO性能
降低数据恢复用时,提高数据恢复效率
AOF重写的规则:

AOF重写的方式:
1、手动重写:bgrewriteaof
案例演示:
第一步、

第二步、

第三步、重写

第四步、

AOF手动重写---bgrewriteaof指令工作原理

2、自动重写:
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage

注意:info指令,查看当前redis运行属性值!!!
AOF工作流程:

基于everysec开启重写

2.17 RDB和AOF的区别


2.18 持久化应用场景

三、Redis事务
3.1 事务简介
redis事务就是一个命令执行的队列,将一系列预定义命令包装成一个整体(一个队列)。当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰;在开发中一般不使用redis事务,作为一个了解就好。
一个队列,一次性、顺序性、排他性的执行一系列命令

3.2 事务的基本操作
开启事务:multi
作用:设定事务的开始位置,此指令执行后,后续的所有指令均加入到事务中
执行事务:exec
作用:设定事务的结束位置,同时执行事务。与multi成对出现,成对使用

注意:加入事务的命令暂时进入到任务队列中,并没有立即执行,只有执行exec命令才开始执行
3.3 事务定义过程中发现问题了怎么处理?
取消事务:discard
作用:终止当前事物的定义,发生在multi命令之后,exec命令之前

3.4 事务的工作流程
set指令:

multi开启事务:

来一个set指令加入队列:

再来一个del指令加入队列:

来一个exec指令:执行了exec指令以后,队列消失

来一个discard指令:直接销毁掉队列里面的指令集

3.5 事务定义过程中,命令格式输入错误怎么办




3.6 事务-锁
一、业务场景一介绍

解决方案:
对key添加监视,在执行exec前如果key发生了变化,终止事务执行
watch key1 [key2,...]

注意:开启watch监控要在开启事务之前,开启watch指令监控的东西如果发生改变,定义的事务将不会执行 ,返回一个nil


取消对key的所有监视:
unwatch


二、业务场景二介绍

基于特定条件的事务执行--分布式锁:
1、使用setnx设置一个公共锁,不存在key才能设置成功,存在则不能设置也不能替换 setnx lock-key value

利用setnx命令返回值的特征,有值则返回设置失败,无值则返回设置成功
对于返回设置成功的,拥有控制权,进行下一步的具体业务操作;对于返回设置失败的,不具有控制权,排队或等待

2、操作完毕使用del释放锁

3.7 事务-死锁
一、业务场景一介绍

解决方案:
使用expire为锁key添加时间限定,到时不释放,放弃锁
expire lock-key second



pexpire lock-key milliseconds
由于操作通常都是微妙或毫秒级,因此该锁定时间不宜设置过大,具体时间需要业务测试后确定

注意这个参数选择!!!

四、删除策略
4.1 redis数据特征
redis是一种内存级数据库,所有数据均存放在内存中,内存中的数据可以通过ttl指令获取其状态



4.2 redis数据删除策略
数据删除策略的目标:
在内存占用与CPU占用之间寻找一种平衡,顾此失彼都会造成redis性能下降,甚至引发服务器宕机或者是内存泄漏
数据删除的方式:
定时删除:

惰性删除:

定期删除:



4.3 redis逐出算法





4.4 服务器配置
服务器端基础配置:

日志配置:

注意:日志级别开发期设置为verbose,生产环境中设置为notice,简化日志输出量,降低写日志IO频度
客户端配置:

多服务器快捷配置:

五、高级数据类型
5.1 搁置
六、主从复制
6.1 互联网“三高”架构
高并发
高性能
高可用


多台服务器连接方案:


主从复制:

高可用集群:

主从复制的作用:

主从复制工作流程:

1、建立连接工作流程

2、实现连接
方式一、客户端发送命令
![]()
master端



![]()

slave端


![]()


方式二、启动服务器参数

master端:

slave端:


方式三、服务器配置

master端:

slave端:





3、主从断开连接

master端:

slave端:先执行下面命令


4、授权访问

七、哨兵
7.1 待完善
八、集群
8.1 待完善
九、企业级解决方案
9.1 缓存预热
宕机:服务器启动后迅速宕机
问题排查:
1. 请求数量较高
2. 主从之间数据吞吐量较大,数据同步操作频度较高
解决方案:
前置准备工作:
1. 日常例行统计数据访问记录,统计访问频度较高的热点数据
2. 利用LRU的数据删除策略,构建数据留存队列,列如:storm与kafka配合
准备工作:
3. 将统计结果中的数据进行分类,根据级别,redis优先加载级别较高的热点数据
4. 利用分布式多服务器同时进行数据读取,提速数据加载过程
实施:
1. 使用脚本程序固定触发数据预热过程
2. 如果条件允许,使用了CDN(内容分发网络)效果会更好
总结:缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统,避免用户在请求的时候先请求数据库然后再缓存的问题,用户直接查询事先预热的缓存数据!
9.2 缓存雪崩
数据库服务器崩溃(1)
1. 系统平稳运行过程中,忽然数据库连接量激增
2. 应用服务器无法及时处理请求
3. 对外响应408超时,或者响应500错误页面
4. 用户得不到反馈数据,反复刷新页面
5. 请求量越来越大,数据库崩溃
6. 应用服务器崩溃
7. 重启应用服务器无效
8. redis服务器开始崩溃
9. redis集群崩溃
10. 重启数据库后再次被瞬间流量放倒
问题排查:
1. 在一个较短的时间内“缓存中较多的key集中过期”
2. 在此周期内请求访问过期数据,redis未命中,redis向数据库获取数据
3. 数据库同时接收到大量请求无法及时处理
4. redis大量请求被积压,开始出现超时现象
5. 数据库流量增大,数据库崩溃
6. 重启后依然面对缓存中无数据可用
7. redis服务器资源被严重占用,redis服务器崩溃
8. redis集群呈现崩塌,集群瓦解
9. 应用服务器无法及时得到数据响应请求,客户端用户继续刷新,来自客户端的请求数量越来越多,应用服务器崩溃
10. 应用服务器、redis、数据库全部重启,效果依然不理想(重启只是给自己一个心理安慰罢了,redis缓存依然没有数据,必崩)
分析问题
1. 短时间内
2. 大量key集中过期
解决方案(道):
1. 更多的页面静态化处理 (原因是页面过多的数据从缓存取)
2. 构建多级缓存结构:Nginx缓存 + redis缓存 + ehcache缓存(纯Java的进程内缓存框架)
3. 检测mysql严重耗时业务进行优化,对数据库的瓶颈排查:列如超时查询、耗时较高事务等
4. 灾难预警机制,监控redis服务器性能指标
CPU占用,CPU使用率 (雪崩的典型现象CPU比较忙)
内存容量
查询平均响应时间
线程数
5. 限流、降级
短时间内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
解决方法(术):
1. LRU与LFU切换
2. 数据有效期策略调整
根据业务数据有效期进行错峰,假如A类90分钟,B类80分钟,C类70分钟
过期时间使用固定时间 + 随机值形式,稀释集中到期的key的数量,比如A类某某key90.1,A类另一key90.5等
3. 超热数据使用永久key(区分超热普通热点)
4. 定期维护(自动 + 人工)
对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据延时
5. 加锁(慎用)
拿到锁的干活,拿不到锁的就拿不到数据
总结:
1. 不管是道的层面还是术的层面,都要去做监控预防,道的话就是平时该怎么去设计,术的话就是出现问题要知道该去动哪些东西
2. 缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如果能有效避免过期时间集中,可以有效解决雪崩现象的出现(约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整

9.3 缓存击穿
数据库服务器崩溃(2)
1. 系统平稳运行过程中
2. 数据库连接量瞬间激增
3. redis服务器内key无大量过期
4. redis内存平稳,无波动
5. redis服务器CPU正常
6. 数据库崩溃
问题排查:
1. redis中某个key过期,该key访问量巨大
2. 多个数据请求从服务器直接压到redis后,均未命中
3. redis在短时间内发起了大量对数据库中同一数据的请求
问题分析:
1. 单个key高热数据
2. key过期
解决方案(术):
1. 预先设定:
以电商为例,每个商家根据店铺等级,指定若干款主打产品,在购物节期间,加大此类信息key的时长
注意:不仅仅是购物街当天,以及后续若干天,访问峰值呈现主键降低的趋势
2. 现场调整:
监控访问量,对自然流量激增的数据延长过期时间,或者设置为永久性key
3. 后台刷新数据:
启动定时任务,高峰期来临之前,刷新数据有效期,确保不丢失
4. 二级缓存:
设置不同的失效时间,保障不会同时失效就行 (还是尽量分类设置过期时间,同类的商品key过期时间都加随机值浮动)
5. 加锁:
分布式锁,防止被击穿,但是要注意也是性能瓶颈,慎重! (不太推荐,实在没有办法的时候考虑使用)
总结:
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与及时调整策略,毕竟单个key的过期监控难度较高,配合雪崩处理策略即可。
9.4 缓存穿透
数据库服务器崩溃(3)
1. 系统平稳运行过程中
2. 应用服务器流量随时间增量较大
3. redis服务器命中率随时间逐步降低 (redis命中率降低,对应数据库服务压力变大)
4. redis内存平稳,内存无压力
5. redis服务器CPU占用激增
6. 数据库服务器压力激增
7. 数据库崩溃
问题排查:
1. redis中大面积出现未命中
2. 出现非正常的URL访问
a、假设百度搜索redis关键字
![]()
b、点击关键字
![]()
c、得到正常的URL访问结果

![]()
d、假设随意修改URL的文章id编号进行访问
![]()
e、得到这么个结果,redis未命中,直接进到数据库查询

问题分析:
1. 获取的数据在数据库中也不存在,数据库查询未得到对应的数据
2. redis获取到null数据未进行持久化,直接返回
3. 下次此类数据到达,重复上述过程
4. 出现黑客攻击 (黑客想办法在穿透redis来对数据库进行攻击,这种攻击不是为了搞数据,通过大量无效URL访问让服务器无法命中,然而给数据库带来较大的流量,导致数据库被整崩掉)
解决方案(术):
1. 缓存null
对查询结果为null的数据进行缓存(长期使用,定期清理),设定短时限,例如30秒-60秒,最高5分钟,时间太久就导致内存泄露 (不是一个有效的解决方案,要是一下来几十万个数据,内存占用短时间瞬间起来)
内存泄露:程序在申请内存后无法释放已经申请的内存空间,一次性内存泄露可以忽略,但内存泄露堆积后果很严重,memory leak(内存泄露)最终会导致 out of memory(内存不足) ,这块内存不释放,就不能再使用了,就叫这块内存泄露了。
内存溢出:是程序在申请内存时,没有足够的内存空间供其使用。比如你需要10M的内存空间,内存空间只剩8M,这就会出现内存溢出。就是说分配的内存不足以放下数据项序列,称为内存溢出。
2. 白名单策略
提前预热各种分类数据id对应bitmaps,id作为bitmaps的offset,相当于设置了数据白名单。当加载正常数据时放行,加载异常数据时直接拦截(效率偏低)。
使用布隆过滤器
3. 实施监控
实时监控redis命中率(业务正常范围时,通常会有一个波动值)与null数据的占比
非活动时段波动:通常检测3-5倍,超过5倍纳入重点排查对象
活动时段波动:通常检测10-50倍,超过50倍纳入重点排查对象
根据倍数不同,启动不同的排查流程,然后使用黑名单进行防控
4. key加密
问题出现后,临时启动防灾业务key,对key进行业务层传输加密服务,设定校验程序,过来的key校验
列如每天随机分配60个加密串,挑选2到3个,混淆到页面数据id中,发现key不满足访问规则,驳回数据访问
总结:
1. 缓存击穿访问了不存在的数据,跳过了合法数据的redis数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类数据的出现量是一个较低的值,当出现此类情况以毒攻毒,及时报警。应对策略应该在临时预案防范方面多做文章
2. 无论是白名单还是黑名单,都是对整体系统的压力,警报解除后尽快移除
9.5 性能指标监控
监控指标

1. 性能指标

2. 内存指标

3. 基本活动指标

4. 基本活动指标

5. 基本活动指标

监控方式:

命令:
benchmark


monitor命令:打印服务器调试信息
slowlog命令:

【原创】 Redis入门、第一部分

Reids数据库基础知识
一、Redis简介
1.1 问题现象

1.2 NoSql
NoSql:Not-Only-Sql(泛指非关系型的数据库),“作为关系型数据库的补充”
作用:应对给予海量用户和海量数据前提下的数据处理问题
特征:不遵循SQL标准、远超于SQL性能、不支持ACID
NoSql应用场景:对数据高并发的读写、海量数据的读写、对数据高可扩展性
NoSql不适合的场景:需要事务支持、基于SQL的结构化查询,处理复杂的关系
常见的NoSql数据库:Redis、memcache、HBase、MongoDB


1.3 Redis
概念:Redis(Remote Dictionary Sever) 使用C语言开发的一个开源的高性能键值对(key-value)数据库
1.4 Redis特征


redis是一个单线程+多路I/O复用机制;memcached是多线程+锁机制

1.5 Redis的应用

1.6 Redis在windows下的安装

1.7 命令行模式工具使用思考
功能性命令
清楚屏幕信息
帮助信息查询
退出指令
二、Redis基础操作
2.1 信息添加
功能:设置key、value数据
命令:set key value
2.2 信息查询
功能:根据key查询对应的value,如果不存在,返回 nil
命令:get key
2.3 清除屏幕信息
功能:清除屏幕中的信息
命令:clear
2.4 帮助
功能:获取命令帮助文档,获取组中所有命令信息名称
命令:help 命令名称 help @组名(help 空格 table)


2.5 退出
功能:退出客户端
命令:quit exit esc(这个玩意儿慎用)
三、Redis数据类型
3.1 数据业务使用场景介绍


3.2 数据存储类型基本介绍
Redis有5大数据存储类型,分别是string、hash、list、set、sorted_set
redis数据存储格式:
redis自身是一个Map,其中所有的数据都采用key:value的形式存储
数据类型:指的是存储的数据类型,也就是value部分的类型,key部分永远都是字符串

3.2.1 string类型
存储的数据:单个数据,最简单的数据存储类型,也是最常用的数据存储类型
存储数据的格式:一个存储空间保存一个数据
存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
string类型数据的基本操作:
操作成功提示integer 1 操作失败提示integer 0
a、添加/修改数据:set key value
b、获取数据:get key
c、删除数据:del key
d、添加/修改多个数据:mset key1 value1 key2 value2
e、获取多个数据:mget key1 key2
f、获取数据字符个数(字符串长度):strlen key
g、追加信息到原始信息后部(如果原始信息存在就追加,否则新建):append key value

string类型数据的扩展操作:
a、设置数值数据增加指定范围的值
指定键的value值加1:incr key

指定键的value值加上指定整数值:incrby key increment


指定键的value值加上指定浮点数值:incrbyfloat key increment

b、设置数值数据减少指定范围的值
decr key

decrby key decrement

c、设置数据具有指定的生命周期
setex key seconds value

psetex key milliseconds value

为key设置过期时间 expire key seconds

获取值的范围 getrange key start end

string作为数值操作:
string在redis内部存储默认就是一个字符串,当遇到增减类操作incr,decr时会转成数值类型进行计算
string的所有操作都是原子性的,采用单线程处理所有业务,命令是一个一个执行的,因此无需考虑并发带来的数据影响
注意:按数值进行操作的数据,如果原始数据不能转成数值,或超越了redis数值上限范围,将报错
提示:
1、redis用于控制数据库表主键id,为数据库表主键提供生成策略,保证数据库表的主键唯一性;此方案适用所有数据库,且支持数据库集群
2、redis控制数据的生命周期,通过数据是否失效控制业务行为,适用于所有具有时效性限定控制的操作
string类型数据操作注意事项:
1、数据操作不成功的反馈与数据正常操作之间的差异

2、数据未获取到
nil等同于null
3、数据最大存储量
string类型数据,单个value最大存储量512MB
string类型应用场景:


说明: 表名:主键字段:主键值:说明字段(粉丝、关注量等等...)

用json形式存放一组数据

注意:数据库中的热点数据key命名案例

3.2.2 hash类型
新的存储需求:对一系列存储的数据进行编组,方便管理,典型应用存储对象信息

需要的存储结构:一个存储空间保留多个键值对数据

hash类型数据的基本操作
a、添加/修改数据:hset key field value

b、获取数据:hget key field hgetall key

c、删除数据:hdel key field1 field2

d、添加/修改多个数据:hmset key field1 value1 field2 value2
![]()
e、获取多个数据:hmget key field1 field2

f、获取hash表中字段的数量:hlen key

g、获取hash表中是否存在指定的字段:hexists key field

hash类型数据的扩展操作
a、获取hash表中所有的字段名或字段值:hkeys key hvals key


b、设置指定字段的数值数据增加指定范围的值:hincrby key field increment(指定字段增加整数) 、 hincrbyfloat key field increment(指定字段增加浮点数)


hash类型数据操作注意事项:
1、hash类型下的value只能存储字符串,不允许存储其它类型数据,不存在嵌套现象。如果数据未获取到,对应的值为 nil
2、每个hash可以存储2的32次方-1个键值对
3、hash类型十分贴近对象的数据存储形式,并且可以灵活的添加删除对象属性,但hash设计初衷不是为了存储大量对象而设计的,切记不可滥用,更不可以将hash作为对象列表使用
4、hgetall操作可以获取全部属性,如果内部field过多,遍历整体数据效率就会低,有可能成为数据访问瓶颈
hash类型应用场景:
1、电商网站购物车设计与实现(属于买家)




当前仅仅是将数据存储到了redis中,并没有起到加速的作用,商品信息还需要二次查询数据库


hsetnx key field value 在此场景的使用:如果当前key中对应的field有值,就什么都不做;如果没值,我就把它加进去!!!

2、双十一活动,销售手机充值卡的商家对移动、联通、电信的30元、50元100元商品推出的抢购活动,比如商品抢购上限1000单(属于卖家)



业务场景:
string存对象(json)与hash存对象的优缺点,string讲究整体性,数据一次性整体操作,要么一次性更新要么一次性读取,以读为主;而hash因为有field字段把属性隔离开,讲究更新操作更具有灵活性,以更新为主!!! 开发的时候根据需求灵活设置数据类型
3.2.3 list类型
数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
需要的存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序
list类型:保存多个数据,底层使用双向链表存储结构实现,哪边都能进 哪边都能出


list类型数据的基本操作
a、添加/修改数据:lpush key value [value ...] rpush key value [value ...]

b、获取数据/查询数据:
lrange key start stop 获取列表指定范围的元素,lrange key start stop ,这里的start代表开始,stop代表结束,当stop为-1的时候表示取到最后一个值,当stop为-2的时候,表示取到倒数第二个值,以此类推;lrange key 0 -1,表示全部取出
左边进去的1 2 3 ,左边查询出来3 2 1

右边进去的 1 2 3,左边查询出来 1 2 3

c、lindex key index ,通过索引从列表中获取/查询元素

d、llen key ,获取链表的长度

e、从左边“移除”数据(移出、弹出),lpop key,当队列中数据移出完以后会删掉key

f、从右边“移除”数据(移出、弹出), rpop key,当队列中数据移出完以后会删掉key

list类型数据的扩展操作
规定时间内获取并移除数据
a、 blpop key [key ...] timeout 删除并获取列表的第一个元素,或阻止直到有可用的元素

拿不出来就一直在那儿等,直到设置时间到,返回nil


b、 brpop key [key ...] timeout 删除并获取列表的第一个元素,或阻止直到有可用的元素

list类型数据操作注意事项:
1、list中保存的数据都是string类型的,数据总量是有限的,最多2的32次方-1个元素(4294967295)
2、list具有索引的概念,但是操作数据时通常以队列的形式进行入队出队操作,或以栈的形式进行入栈出栈操作
3、获取全部数据操作结束的索引设置为-1
4、list可以对数据进行分页操作,通常第一页的信息来自于list,第2页及更多的信息通过数据库的形式加载
list类型应用场景:
1、微信朋友圈点赞,要求按照点赞顺序现实点赞好友信息

从列表中删除元素,移除指定数据,lrem key count value


2、新浪微博、腾讯微博中个人用户的关注列表需要按照用户的关注顺序进行展示,粉丝列表需要将最近关注的粉丝列在前面




3.2.4 set类型
数据存储需求:存储大量的数据,在查询方面提供更高的效率
需要的存储结构:能够保存大量的数据,高效的内部存储机制,便于查询
set类型:与hash存储结构完全相同,仅存储键,不存储值(nil),并且值是不允许重复的


set类型数据的基本操作
a、添加数据:sadd key member [member ...]

b、获取全部数据:smembers key

c、删除数据:srem key member [member ...]

d、获取集合数据总量:scard key

e、判断集合中是否包含指定数据:sismember key member

set类型应用场景:
1、应用场景举例1

set类型数据的扩展操作:
a、随机获取集合中指定数量的数据:srandmember key [count]

b、随机获取集合中的某个数据并将该数据移出集合:spop key

提示:redis应用于随机推荐类信息检索,列如热点歌单推荐,热点新闻推荐,热卖旅游路线推荐,应用APP推荐,大V推荐等
2、应用场景举例2


c、求两个集合的交集:sinter key [key ...]

d、求两个集合的并集:sunion key [key ...]

e、求两个集合的差集:sdiff key [key ...]

f、求两个集合的交集、并集、差集并存储到指定的集合中


g、将指定数据从原始集合中移动到目标集合中:smove source destination member

提示:

set类型数据注意事项:
1、set类型不允许数据重复,如果添加的数据在set中已经存在,将只保留一份

2、set虽然与hash存储结构相同,但是无法启用hash中存储至的空间

3、应用场景举例3



校验工作:redis提供基础数据还是提供校验结果? 尽量提供基础数据,不在redis数据端做数据校验
4、应用场景举例4


提示:redis应用于同类型数据的快速去重
5、应用场景举例5


3.2.5 sotred_set类型
数据存储需求:数据排序有利于数据的有效显示,需要提供一种可以根据自身特征进行排序的方式
需要的存储结构:新的存储模型,可以保存可排序的数据
sorted_set类型:在set的存储结构基础上添加可排序字段

sorted_set数据的基本操作:
a、添加数据:zadd key [NX|XX] [CH] [INCR] score member [score memb

b、获取全部数据(从小到大):zrange key start stop [WITHSCORES]


加了参数withscores以后的结果:

c、获取全部数据(从大到小):zrevrange key start stop [WITHSCORES]

d、删除数据:zrem key member [member ...]

e、按条件获取数据(从小到大):zrangebyscore key min max [WITHSCORES] [LIMIT offset count]

f、按条件获取数据(从大到小):zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]

附加limit条件查询:

g、按条件索引删除数据:zremrangebyrank key start stop

h、按条件删除数据:zremrangebyscore key min max


i、获取集合数据总量:zcard score

j、统计集合某个范围的数据:zcount key min max

k、集合交集操作:zinterstore destination numkeys key [key ...] [WEIGHTS weight] [AG

sorted_set类型应用场景:
1、应用场景举例1

m、获取数据对应的索引(由小到大):zrank key member

n、获取数据对应的索引(由大到小):zrank key member

o、score值得获取

p、score值修改

提示:

sorted_set类型数据注意事项:
1、score保存的数据存储空间是64位,如果整数范围是-9007199254740992~9007199254740992
2、score保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度,使用时候要慎重
3、sorted_set底层存储还是基于set结构,因此数据不能重复,如果重复添加相同的数据,score将被反复覆盖,保留最后一次修改结果


【原创】 PHP8

PHP8的使用
1、 PHP基本介绍
1.1、什么是PHP

1.2、PHP是怎么执行的

2、PHP8介绍
PHP8是PHP语言的一个主版本更新,它包含了很多新功能与优化,包括命名参数、联合类型、注解、构造器属性提升、match表达式、nullsafe运算符、JIT、并改进了类型系统、错误处理、语法一致性。
2.1、JIT(即时编译)编译器
JIT(Just-In-Time)即时编译器,是PHP8.0中最重要的新功能之一,可以极大地提高性能。
JIT编译器将作为扩展集成到php中Opcache扩展,用于运行时讲某些操作码直接转换为cpu指令。仅在启用Opcache的情况下,JIT才有效。
2.2、Opcache扩展
Opache将通过PHP脚本预编译的字节码存储到共享内存中来提升PHP的性能,存储预编译字节码的好处就是:省去了每次加载和解析PHP脚本的开销。
Opcache开启:
zend_extension=opcache
Opcache配置:

JIT配置:在php.ini中,加到上面opcache配置后面
opcache.jit=tracing
opcache.jit_buffer_size=100M
【原创】 内存分析
计算机内存分析介绍
1、计算机内存组成
1.1、计算机内存结构介绍
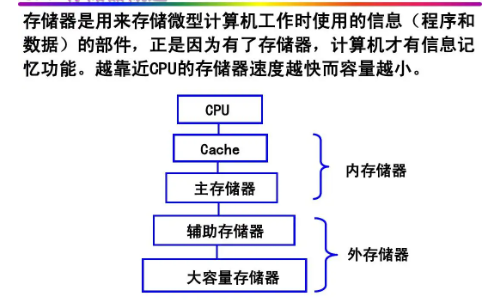
在计算机中,内存又称主存储器,是CPU能够直接寻址的存储空间,由半导体器件制成,主要由存储体、控制线路、地址寄存器、数据寄存器、和地址译码电路五部分组成。
在计算机组成结构中有一个很重要的部分是存储器,它是用来存储程序和数据的部件。对计算机来说,有了存储器才有记忆功能,才能保证正常工作。存储器的种类很多,按其用途可分为主存储器和辅助存储器,主存储器又称为内存储器,内存又称为主存,是CPU能够直接寻址的存储空间,与辅助存储器相比,有容量小、读写速度快、价格高等特点。
1.2、技术指标
存储容量:在一个存储器中可以容纳存储单元总数的大小、字节数。
存取时间:启动到完成一次存储操作所经历的时间,主存速度单位ns。
存储周期:连续启动两次操作所需间隔的最小时间,主存速度单位ns。
存储器带宽:单位时间内存储器所存取的信息量,它是衡量数据传输速率的重要指标单位是b/s(位/秒),或者是B/S(字节/秒)。
存放一个机器字的存储单元,通常称为字存储单元,相应的单元地址叫字地址。而存放一个字节的单元,称为字节存储单元,相应的地址称为字节地址。如果计算机中可编址的最小单位是字存储单元,则该计算机称为按字编址的计算机。如果计算机中可编址的最小单位是字节,则该计算机称为按字节编址的计算机。一个机器字可以包含数个字节,所以一个存储单元也可以包含数个能够单独编址的字节地址。例如,PDP-11系列计算机,一个16位二进制的字存储单元可存放两个字节,可以按字地址寻址,也可以按字节地址寻址。当用字节地址寻址时,16位的存储单元占两个字节地址。
2、内存数据存放
2.1、大端和小端存储
小端:就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
大端:就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。

2.2、由什么决定存储方式
需要说明的是,计算机采用大端存储还是小端存储是由CPU来决定的,我们常用的X86体系CPU采用的是小端存储,ARM也是采用的小端存储,但有些CPU却采用的大端,比如:Sun、PowerPC
3、数据在内存中的形式
数据在内存中是以二进制形式存放的,数值是以补码表示的;字符、汉字、特殊符号等都有对应的码值(ASCII/unicode码的码值),对应字符的码值转换成二进制数存放在内存中
【原创】 Mysql数据库入门、第二部分

Mysql数据库基础知识
九、MYSQL约束
9.1 约束基本介绍
约束用于确保数据库数据满足特定的商业规则,在mysql中,约束包括not null(非空)、unique(唯一)、primary key(主键)、foreign key(外键)、check(检查)五种
9.1.1、主键使用方式:字段名 类型 primary key
primary key主键基本作用:用于唯一的表示表行的数据,当定义主键约束后,该列不能重复
应用实例一:演示主键的使用
第一步:创建表

第二步:添加数据

primary key主键使用细节讨论:
1、primary key不能重复且值不能为空
2、一张表最多只能有一个主键,但可以是复合主键,多个字段合起来是一个主键
应用实例一:复合主键使用
错误:

创建复合主键



3、主键的指定方式有两种
一是直接在字段名后面指定:字段名 primary key
二是在表定义的最后写primary key(列名,列名...)

4、可以使用desc 表名 查看primary key的情况

5、在实际的开发中,每个表往往都会设计一个主键
9.1.2、not null(非空)使用方式:字段名 类型 not null
开发中,如果在列上定义了not null,那么在插入数据时,必须为列提供数据
9.1.3、unique(唯一)使用方式:字段名 字段类型 unique
定义了唯一约束后,该列值是不能重复的
应用实例一:演示unique的使用


unique 使用细节讨论:
1、如果没有指定主键的情况下也没有指定not null,则unique字段可以有多个null值

2、如果一个列(字段) 有unique not null 约束,使用效果类似primary key
3、一张表中可以有多个unique 字段
9.1.4、foreign key(外键)使用方式:foreign key (本表(从表、外键表)的字段名)references 主表名(主键名或unique字段名)
外键基本介绍:
外键用于定义主表和从表之间的关系,外键约束要定义在“从表”上,主表则必须具有“主键约束” 或是“unique“约束,当定义外键约束后,“要求外键列数据必须在主表的主键列存在或是为null“

应用实例一:演示外键使用
第一步:创建主表,字段有班级编号、班级名称

第二步:创建从表,字段有学生编号、学生名字、学生所在班级编号(外键)

第三步:添加测试数据

从表设置了外键,主表中没有id为300的数据,所以从表的这条添加的语句不会成功,insert into my_stu values(3,'螳螂',300)[添加失败],但是外键字段的值如果允许为空 (没有设置not null 非空约束),则可以添加成功


外键使用细节讨论:
1、外键指向的表的字段,要求是primary key 或者是unique

2、表的类型必须是innodb,这样的表才支持外键;mysql从5.5版本以后,默认引擎innodb;查看mysql版本使用命令status


3、外键字段的类型要和主键字段的类型一致(长度可以不一样)

4、外键字段的值,必须在主键字段中出现过,或者为null [前提是外键字段允许为null]

5、一旦建立外键关系,数据就不能随意删除了;如果要删除,除非把设置外键的从表中的对应ID的数据都删除,才能去删除主表中的该条ID记录值


9.1.5、check 使用方式:列名 类型 check (check条件)
基本介绍:check用于强制行数据必须满足的条件,假定在之前的员工表的sal列上定义了check约束,并要求sal列值在1000~2000之间,如果不在1000~2000之间就会提示出错; oracle 和 sql server均支持check,但是mysql5.7目前还不支持check,只做语法校验,但不会生效
应用实例一:演示check使用
第一步:创建表

第二步:添加数据 , 一样是能添加到数据表中,所以,只做语法校验,但不会生效

9.2 自增长
在某张表中,存在一个id列(整数),我们希望在添加记录的时候从1开始,自动增长。 使用方式:字段名 整型 primary key auto_increment

应用实例一:演示自增长的使用
第一步:创建表


第二步:添加数据


自增长使用细节讨论:
1、一般来说自增长是和peimary key配合使用的
2、自增长也可以单独使用 [需要配合一个unique]
3、自增长修饰的字段为整数类型的(虽然小数类型也可以,但是非常非常少这样用的)
4、自增长默认从1开始,也可以通过命令修改, alter table 表名 auto_increment = 10(具体整形值)

5、自如果你添加数据时,给自增长字段(列)指定有值,则以指定的值为准;以下图为例,以后再添加数据的时候,id就从667开始了

十、MYSQL索引
10.1 索引基本介绍
说起提高数据库性能,索引是最物美价廉的方案了,不用加内存,不用改程序不用调SQL,查询速度就有可能提高百倍千倍;
说索引之前先说一下mysql安装在硬盘文件目录下面data文件夹中的文件
1、表存储引擎是myisam,在data目录下面会看到3类文件:frm、myi、myd
*.frm-表定义,是描述表结构的文件
*.MYD-"D"数据信息文件,是表的数据文件
*.MYI-"I"索引信息文件,是表数据文件中的任何索引的数据树
2、表存储引擎是InnoDB,在data目录下面会看到2类文件:frm、ibd
*.frm-表定义,是描述表结构的文件
*.ibd-表数据和索引文件,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据
3、另外db.opt文件
用来记录该库的默认字符集编码和字符集排序规则使用的。也就是说你创建数据库指定默认字符集和排序规则,那么后续创建的表如果没有指定字符集和排序规则,那么该新建的表将采用db.opt文件中指定的属性。
10.2 索引原理:
"没有使用索引" 的时候查询过程如下图:
全表扫描,从id最小查询到id最大,即使查询条件是id=1,它也会全表扫描,查询速度非常慢


二叉树简介:
1、二叉树的叶子节点就是没有子节点的节点,一棵树中没有子节点(即度为0),的节点称为叶子节点,简称“叶子”,又称为终端节点。
2、二叉树特点是每个节点最多只能有两颗子树,且有左右之分。
3、二叉树是n个有限元素的集合,该集合或者为空,或者由一个称为根的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树,当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称为一个节点。
建立索引的二叉树(数据结构),在1-9中间找一个位于最大编号id和最小编号id的中间的数,假设是5,比5小的摆放位置在左边,比5大的摆放位置在右边,然后继续在1和5之间中间数,假设为2,然后比2小的继续摆放在2左边,比2大的摆放在2的右边,所有数据按照此方式分析下去

使用了索引的时候查询过程如下图:
第一步:where条件id为1,假设1--9二分,中间找到5,然后5右边的数据就不再查找了,如下图所示

第二步:where条件id为1,1比5小,再往左边再二分,假设1--5中间找到2,然后2右边的数据也不再查找,假设是一个800万的数据中查找,大概是23次左右就能找到,比顺序扫描快了不知道多少多少,如下图所示

二叉树五种基本形态:
图a:空二叉树
图b:只有一个根节点的二叉树
图c:只有左子树
图d:只有右子树